
Python大数据毕业设计:旅游景点评论数据可视化分析项目 毕业设计 选题推荐 毕设选题 数据分析 机器学习
基于Spark的旅游上榜景点及评论数据可视化分析系统


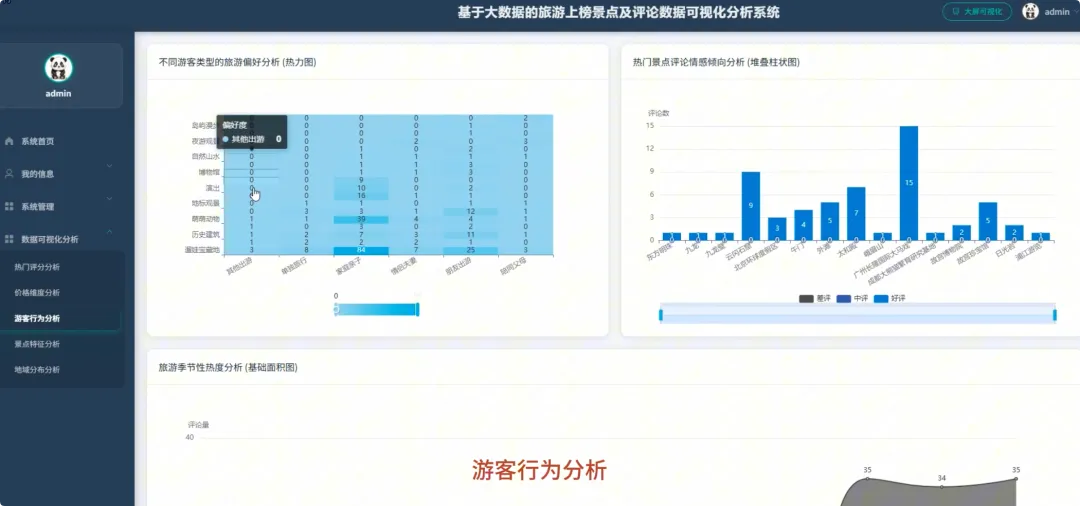
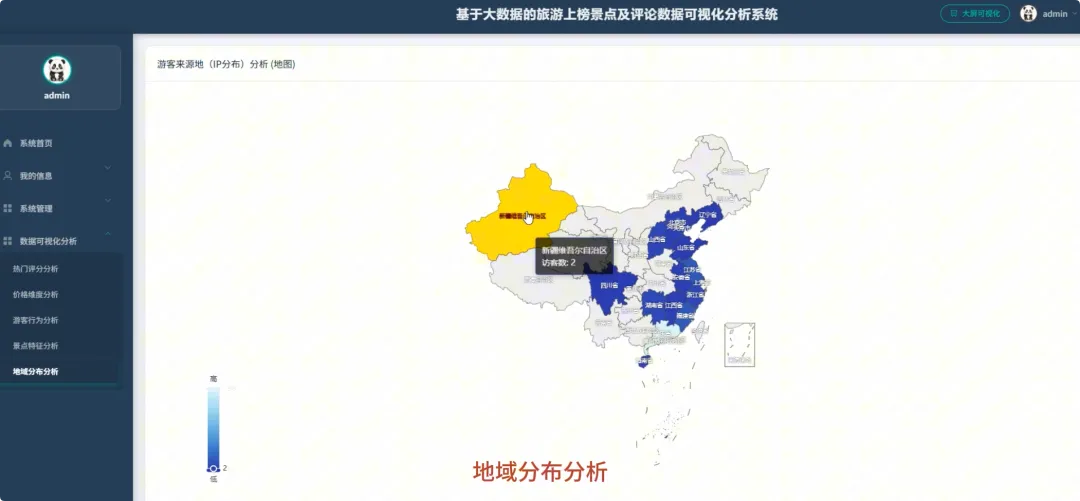
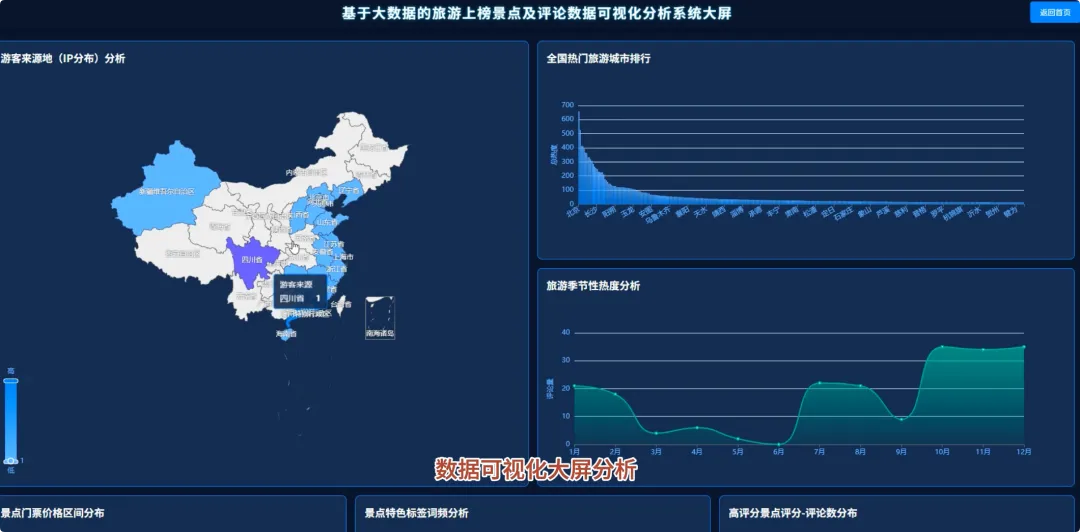
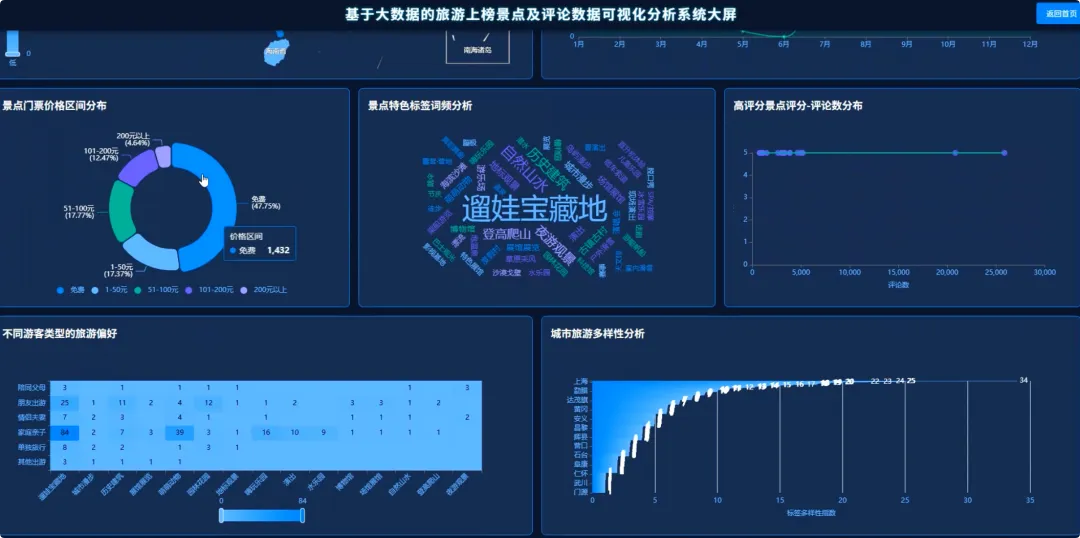
本系统“基于Spark的旅游上榜景点及评论数据可视化分析系统”是一个完整的大数据处理与应用项目,旨在应对海量旅游数据的分析挑战。系统整体采用Hadoop作为数据存储基础,利用HDFS分布式文件系统对景点信息与海量评论数据进行统一管理。核心计算引擎选用Apache Spark,通过其高效的内存计算能力,对TB级数据进行快速处理,其中Spark SQL负责执行结构化数据查询与聚合分析,而PySpark则用于处理复杂的文本分析任务。后端服务采用Python的Django框架,负责将Spark分析处理后的结果数据封装成RESTful API接口,向前端提供数据支持。前端则基于Vue.js和ElementUI构建用户界面,并借助Echarts强大的图表渲染能力,将城市热度排行、景点评分分布、评论情感倾向、游客来源地等多维度分析结果,以动态、交互式的可视化图表形式直观呈现,最终为用户提供一个从数据接入、清洗、分析到可视化展示的全链路解决方案。



选题背景
随着在线旅游平台的蓬勃发展,游客在出行前越来越依赖网络上的景点信息和用户评论来做决策。这导致了旅游相关数据的爆炸式增长,形成了庞大的信息海洋。然而,这些数据往往以零散、非结构化的形式存在,普通游客很难从中快速提炼出有价值的参考信息。比如,一个想去云南旅游的用户,面对成千上万的景点和评论,如何高效地筛选出真正高性价比的目的地?同样,对于旅游城市的规划者或景点的管理者而言,如何从海量的用户反馈中准确把握游客的偏好、发现服务中的短板,也成了一个现实的难题。因此,利用大数据技术对这些宝贵的旅游数据进行系统性的整合与分析,就显得尤为迫切和必要。
选题意义
本课题的意义在于,它尝试为上述问题提供一个切实可行的技术解决方案。对游客而言,系统通过数据可视化的方式,将复杂的分析结果变得通俗易懂,能够帮助他们更科学地规划行程,避开“网红”景点的陷阱,发现真正符合自己需求的“宝藏”目的地,具有一定的消费决策辅助作用。对旅游行业的管理者来说,系统提供的多维度分析报告,比如游客来源地画像、差评关键词分析等,可以为了解客源市场、优化服务策略、提升游客满意度提供客观的数据依据。从技术实践角度看,本项目完整地应用了当前主流的大数据技术栈,将Hadoop、Spark与Web开发技术相结合,为计算机专业的学生提供了一个将理论知识转化为实际项目的优秀范例,探索了一种处理特定领域大数据问题的有效方法。



开发语言:Python或Java
大数据框架:Hadoop+Spark(本次没用Hive,支持定制)
后端框架:Django+Spring Boot(Spring+SpringMVC+Mybatis)(两个版本都支持)
前端:Vue+ElementUI+Echarts+HTML+CSS+JavaScript+jQuery
详细技术点:Hadoop、HDFS、Spark、Spark SQL、Pandas、NumPy
数据库:MySQL








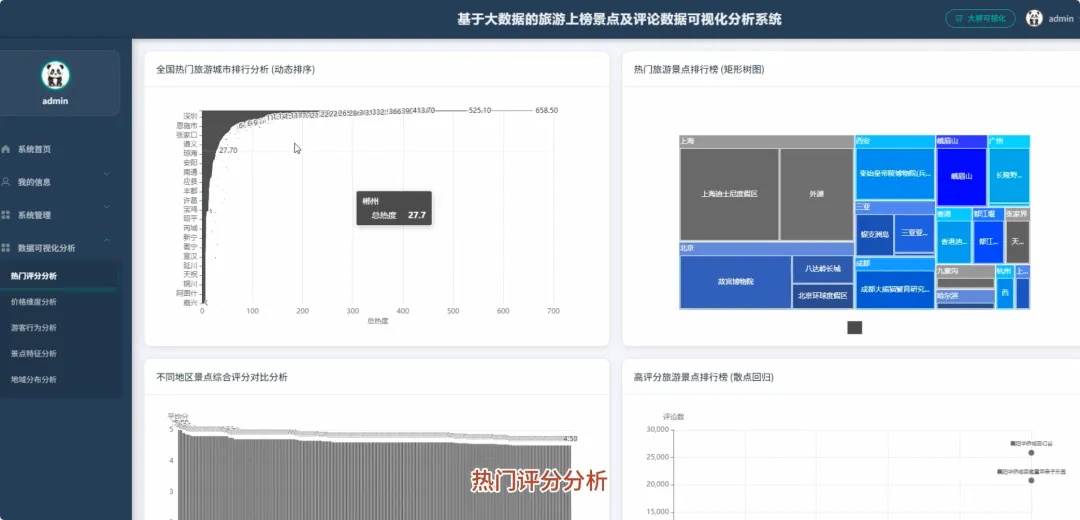
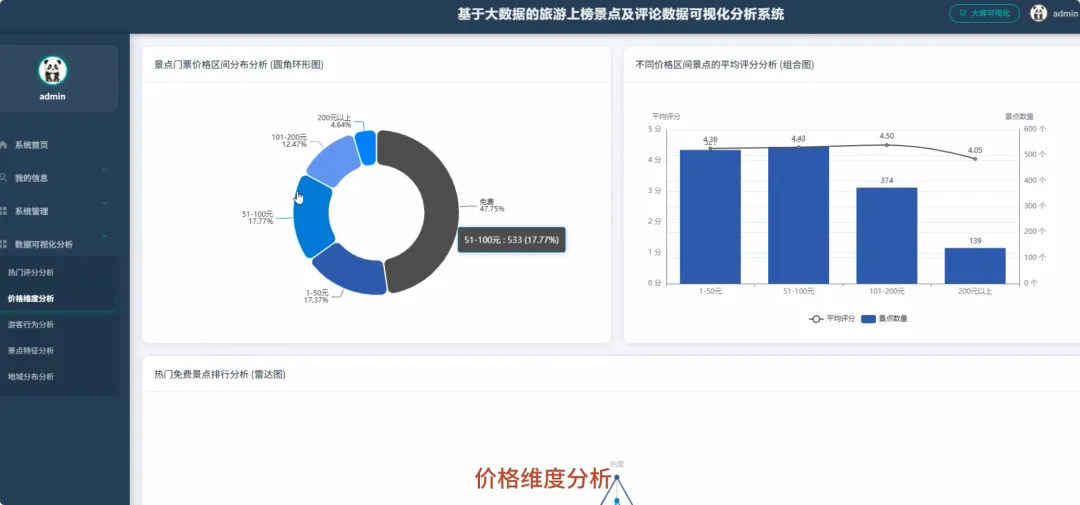



from pyspark.sql import SparkSessionfrom pyspark.sql.functions import col, when, sum, count, descimport jiebaimport respark = SparkSession.builder.appName("TourismDataAnalysis").getOrCreate()# 核心功能1: 全国热门旅游城市排行分析def analyze_hot_cities(spark):sight_df = spark.read.csv("hdfs://namenode:9000/data/sightinfo.csv", header=True, inferSchema=True)sight_df.createOrReplaceTempView("sight_view")hot_cities_df = spark.sql("SELECT districtname, SUM(heatscore) as total_heat FROM sight_view GROUP BY districtname ORDER BY total_heat DESC")pandas_df = hot_cities_df.toPandas()pandas_df.to_csv("/app/results/hot_cities_rank.csv", index=False)return hot_cities_df.show()# 核心功能2: 热门景点评论情感倾向分析def analyze_sentiment(spark):comment_df = spark.read.csv("hdfs://namenode:9000/data/commentinfo.csv", header=True, inferSchema=True)sentiment_df = comment_df.withColumn("sentiment", when(col("score") >= 4, "好评").when(col("score") <= 2, "差评").otherwise("中评"))sentiment_count_df = sentiment_df.groupBy("poiname", "sentiment").agg(count("*").alias("count"))sentiment_pandas_df = sentiment_count_df.toPandas()sentiment_pandas_df.to_csv("/app/results/sentiment_distribution.csv", index=False)return sentiment_count_df.show()# 核心功能3: 游客差评关键词分析def analyze_negative_keywords(spark):comment_df = spark.read.csv("hdfs://namenode:9000/data/commentinfo.csv", header=True, inferSchema=True)negative_comments = comment_df.filter(col("score") <= 2).select("plcontent")stop_words = ["的", "了", "是", "在", "我", "有", "和", "就", "不", "人", "都", "一", "一个", "上", "也", "很", "到", "说", "要", "去", "你", "会", "着", "没有", "看", "好", "还", "这"]words_rdd = negative_comments.rdd.flatMap(lambda row: jieba.cut(row.plcontent))filtered_words_rdd = words_rdd.filter(lambda word: len(word) > 1 and word not in stop_words and not re.match(r'[^\u4e00-\u9fa5]', word))word_counts_rdd = filtered_words_rdd.map(lambda word: (word, 1)).reduceByKey(lambda a, b: a + b)top_keywords = word_counts_rdd.sortBy(lambda x: x[1], ascending=False).take(50)with open("/app/results/negative_keywords.txt", 'w', encoding='utf-8') as f:for word, count in top_keywords:f.write(f"{word},{count}\n")return top_keywords



~~感谢您抽出宝贵时间来阅读此文~~


相关文章
发表评论
评论列表
- 这篇文章还没有收到评论,赶紧来抢沙发吧~