
ICLR'26|旅行攻略背后的智能体难题:ChinaTravel检验LLM Agent在开放世界中的可靠性

导语

南京大学联合华为诺亚方舟实验室提出ChinaTravel,首个面向真实中文开放场景的旅行规划评测基准,用于系统检验大模型智能体在复杂、开放、多约束任务中的语义理解、约束满足与组合泛化能力。与传统旅行规划基准将需求简化为固定槽位 “填空题” 不同,ChinaTravel基于1154位真实用户的原生中文需求,覆盖北京、上海、成都等10座热门城市,包含海量景点、餐厅、酒店与交通数据,更贴近用户真实规划场景。该基准采用可组合的类Python DSL实现约束表达与自动验证,可灵活处理预算、时间、口味、人群、地点等耦合约束,无需逐条编写规则。
本文为文章作者的观点/研究数据,仅供参考,不代表本账号的观点和研究内容。
Project Page: https://www.lamda.nju.edu.cn/shaojj/ChinaTravel/index.html
GitHub: https://github.com/LAMDA-NeSy/ChinaTravel
DataSet: https://huggingface.co/datasets/LAMDA-NeSy/ChinaTravel
Challenge@IJCAI2026: https://chinatravel-competition.github.io/IJCAI2026/

旅行规划:从被简化的“填空选择题”,回到开放的语言需求
从决定“五一去成都玩 4 天”开始,绝大多数人都会先在小红书刷别人的攻略,然后切到携程飞猪订酒店,到12306订车票,用高德查景点之间的距离与车程,再回头比对每天的体力和饭点;最后给小伙伴发一份“姑且能用”的行程,再视情况反复调整。这件事真正难的并不是某一步,而是要把分散在各个App,又彼此耦合的信息整合起来,并随时按家人朋友的口味、预算、时间反复改写。
把这件事交给语言智能体(Language Agent)来做,要求模型通过大量工具收集信息,同时权衡空间、时间、预算、口味、体力等一大堆彼此耦合的变量;想一次性产出一份真能用的行程计划,远比想象中困难。
然而,过去的旅行规划基准,离真实生活中的旅行规划,距离一直不算近。
它们往往把用户意图建模成“选择/填空题”(slot-filling):所有需求被提前压缩成一张预定义的属性表,智能体只需为每个槽位挑选取值。例如 TravelPlanner 用以下五类逻辑约束覆盖测试需求:
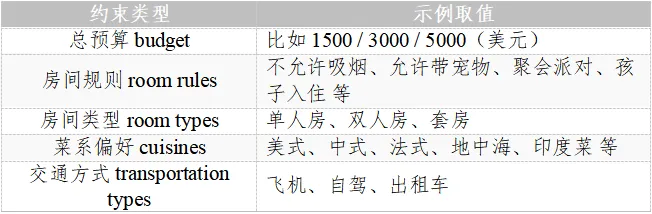
这是一种“封闭的需求理解”:测评者把可能的需求穷举好,智能体只要做“填空/选择题”式的理解。但凡用户表达的需求落在这张预设表之外,benchmark既无法把它建模成约束,也无法验证 agent 是否真的满足了需求。比如:如果用户说“住宿预算控制在800元以内”,而表里的budget只能支持旅程总体预算,那么这条需求则无法被建模,agent 给出的方案是否真的控制在800元以下,benchmark也验证不了。
更值得关注的是,这种简化也让旅行规划的真实难度被严重低估。TravelPlanner发布几个月后,来自MIT的团队就用“LLM抽约束+SMT求解器”的神经-符号(Neuro-Symbolic, NeSy)框架,把它刷到了97%的通过率。
补充说明:神经-符号方法,指把LLM这类“善于理解语言”的神经模块,和约束求解器、规划器这类“善于严格推理”的符号模块组合起来。LLM负责把用户的自然语言需求翻译成机器可执行的约束,符号求解器则在约束下进行可验证的推理与搜索;两者互补,规避了LLM在多步约束推理上的不稳定。
那么现实场景中人类提出的旅行需求,真的可以靠“LLM抽约束+求解器”这套范式解决吗?
事情远没有TravelPlanner上的分数那么乐观。南大×华为的这项ICLR 2026工作指出:从人类志愿者那里收集到的真实旅行需求,往往是用可组合的自然语言表达的,而且常常带有隐式的语义。比如“带不能吃辣的小孩出行”“想尝一尝本地菜”“第二天下午6点前务必到上海”,第一条要求agent自动排除川菜、渝菜;第二条要在不同城市落到不同菜系(在上海是本帮菜,在北京是北京菜);第三条把时间和地点耦合在了一起。光是“理解”这些表达,难度就比TravelPlanner中的slot-filling模式高出一个量级;而能力的边界也随之从“能否完成单一约束”转向“能否在语言需求的组合空间里持续泛化”。
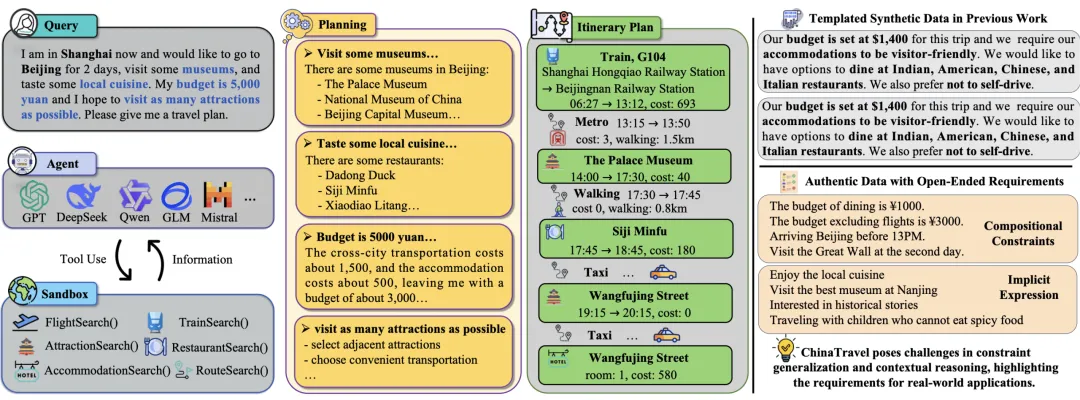
ChinaTravel概览:左侧是从Query到Itinerary Plan的完整Agent工作流(Tool Use + Sandbox + Planning),右侧对比“模板化合成数据”与“开放真实需求”的差异,凸显出组合式约束与隐式语义表达的挑战。

ChinaTravel:走向“开放世界”旅行规划
我们把这个新基准命名为ChinaTravel,核心做了四件事:
真实中国本土场景:覆盖10个热门城市与多源POI/交通数据。已有旅行规划基准(如TravelPlanner)主要面向美国城市的英文需求,与中国用户的真实使用习惯有较大距离。ChinaTravel覆盖北京、上海、成都、重庆等10大热门城市,包含3,413个景点、4,655家餐厅、4,124家酒店,以及 720个航班、5,770趟列车的跨城交通数据。所有API按商业接口模式设计,真正支持多日多POI的时空规划。
组合式验证:用类Python DSL替代穷举规则。已有基准里,每一类约束都得逐条人工定义和验证;新加一类需求,就要重写一次规则,验证机制天然撑不住开放扩展。该论文设计了一套类Python的领域特定语言DSL(Domain-Specific Language),把基础概念(如 cost、dist、type)做成可组合的“积木”函数,让“用餐总花费不超过 1000 元”、“第二天18:00前抵达上海”这类约束都能用DSL展开表达,再交给Python编译器自动验证。新需求只需要重新组合积木,不再需要写新规则。
开放需求表达:收集1,154位真实用户的中文旅行需求。作者团队通过问卷向1,154位真实用户 征集原生中文的旅行需求,经过质控与DSL标注,最终筛选出154条Human-Val验证集和1,000 条Human-Test测试集。这是第一个把“不可穷举的真实人类语言需求”搬进评测集的旅行规划基准。与以往依赖模板合成、或者只有数十条人工示例的 需求相比,这批需求是基于开放语言表达的,更贴近智能体在真实场景中真正会遇到的语言挑战。
统一比较神经-符号范式:从纯LLM到NeSy Planning。神经-符号范式的特色是能够把神经网络的语言理解能力与符号推理的约束满足能力组合起来,让两者优势互补。过去的旅行规划基准主要以纯 LLM方案为主角,缺乏对这条路线的横向参考。该论文把多种神经-符号变体(基于整数规划的TTG、基于验证器反馈的LLM-modulo,以及作者新提出的NeSy Planning)放到统一实验框架下系统比较,借此把当下语言智能体在多日开放规划上的真实瓶颈清晰地刻画出来。

到底“难”在哪里?ChinaTravel三个维度的量化分析
ChinaTravel的难点不是单一约束变难,而是输入规模、约束组合和语义落地同时放大:Agent既看不完、也搜不动,更不一定理解得准。
📈 上下文超长:一次输入压穿DeepSeek-V3与GPT-4o
平均每个query要处理 超过1,200个候选POI,是TravelPlanner的4倍、Trip Planning的120倍。完整候选信息可膨胀到540M tokens,远超DeepSeek-V3(64K)与GPT-4o(128K)的上下文长度;即便做到6-POI的激进下采样,也仍需约40K tokens。这意味着“一次性生成一份完整行程”的传统做法,在真实旅行规划面前直接失效。
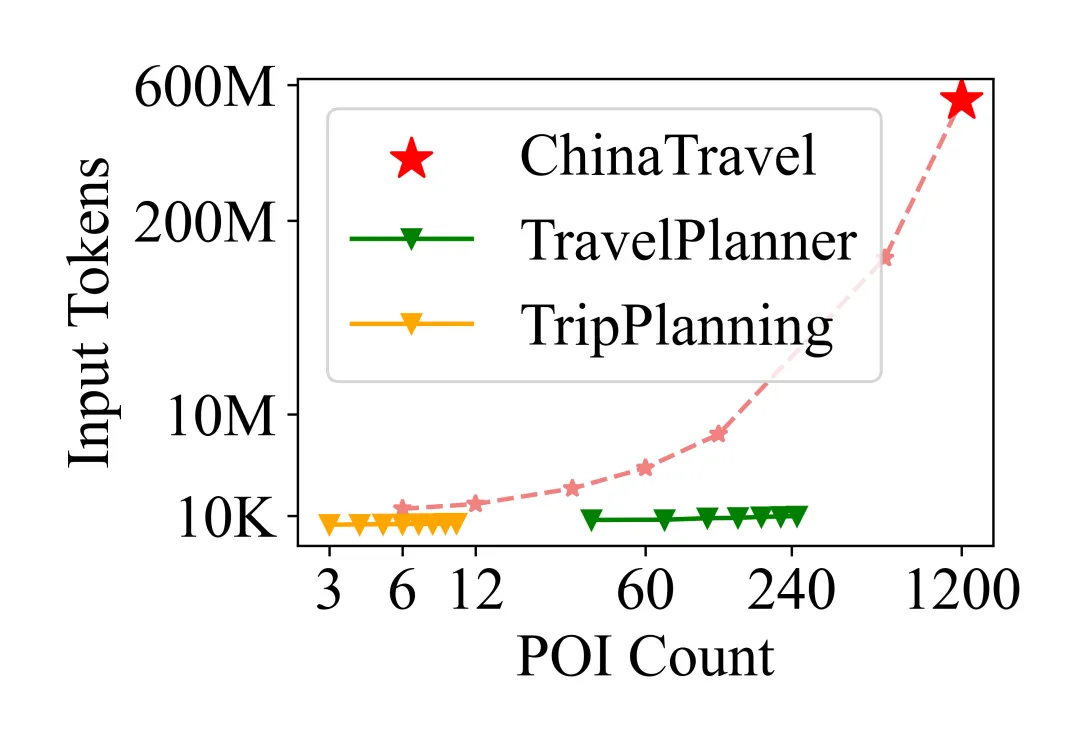
输入上下文token量随候选POI数量增长。ChinaTravel的单query输入规模可达540M tokens。
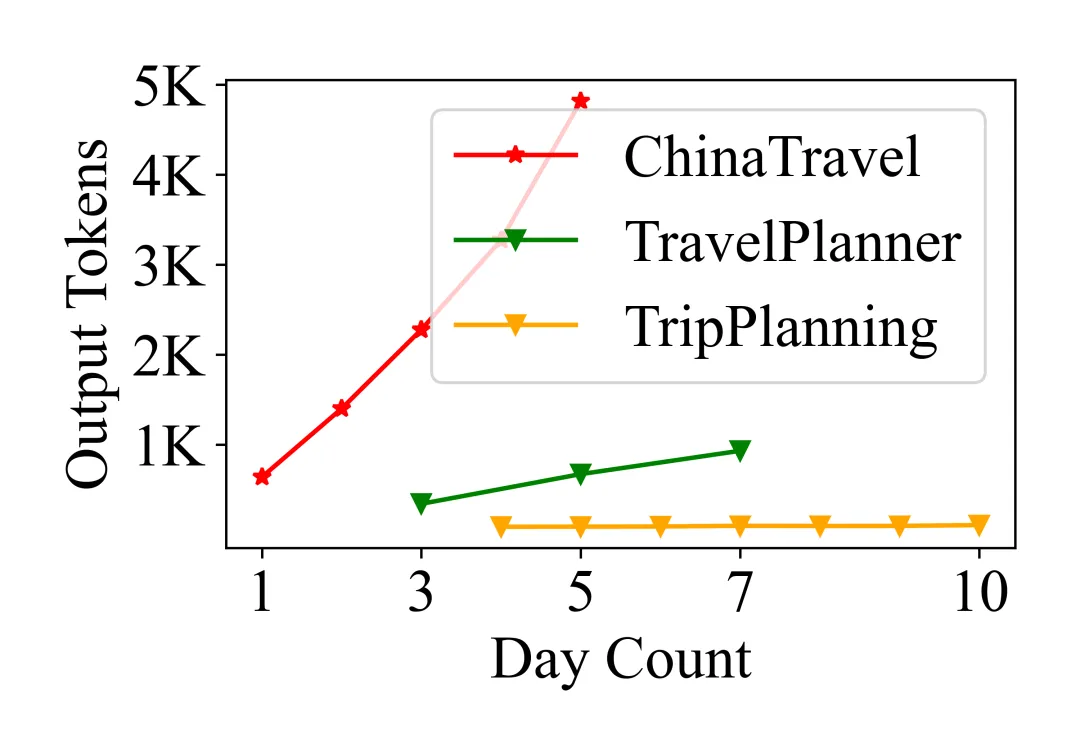
输出规划token量随行程天数增长。5天行程产生4.8K tokens的结构化输出。
📈 约束组合空间爆炸:从10种到100种
TravelPlanner每条query的约束数量偏少(普遍≤5),而ChinaTravel则呈近高斯分布,6–12条是主流。更关键的是组合空间:TravelPlanner的原子约束最多组合出10种类型,而ChinaTravel在Human-Test中出现了100种约束类型,其中85种是开发阶段从未见过的全新组合。
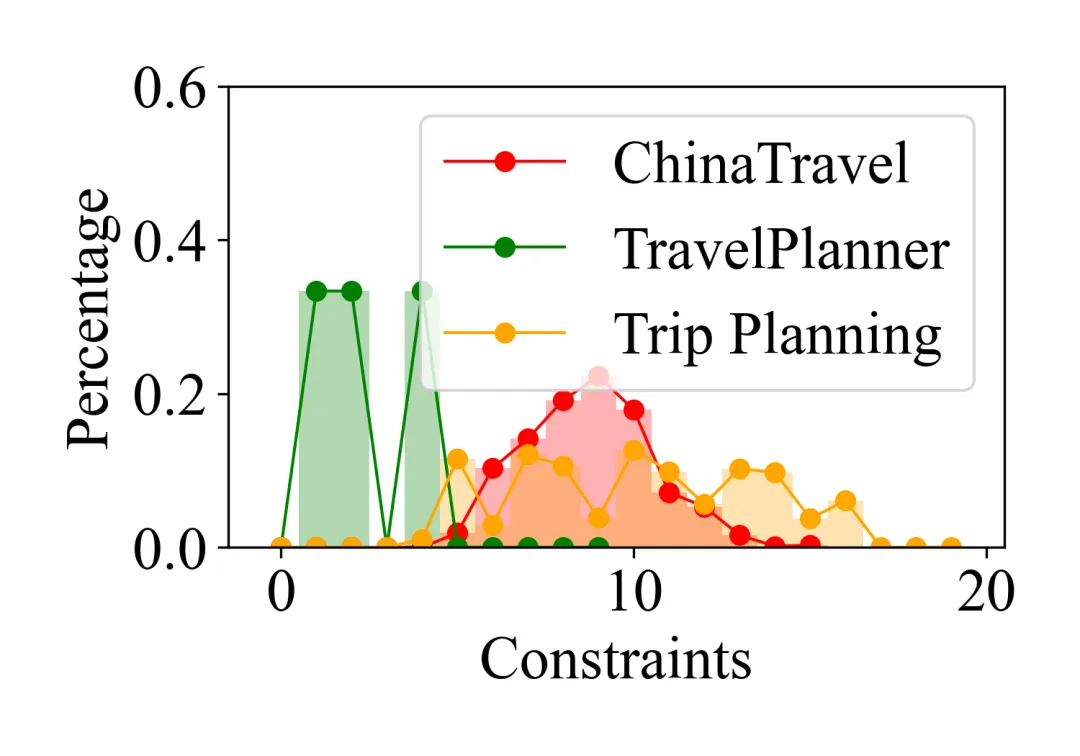
每条Query的旅行需求(约束)个数分布。
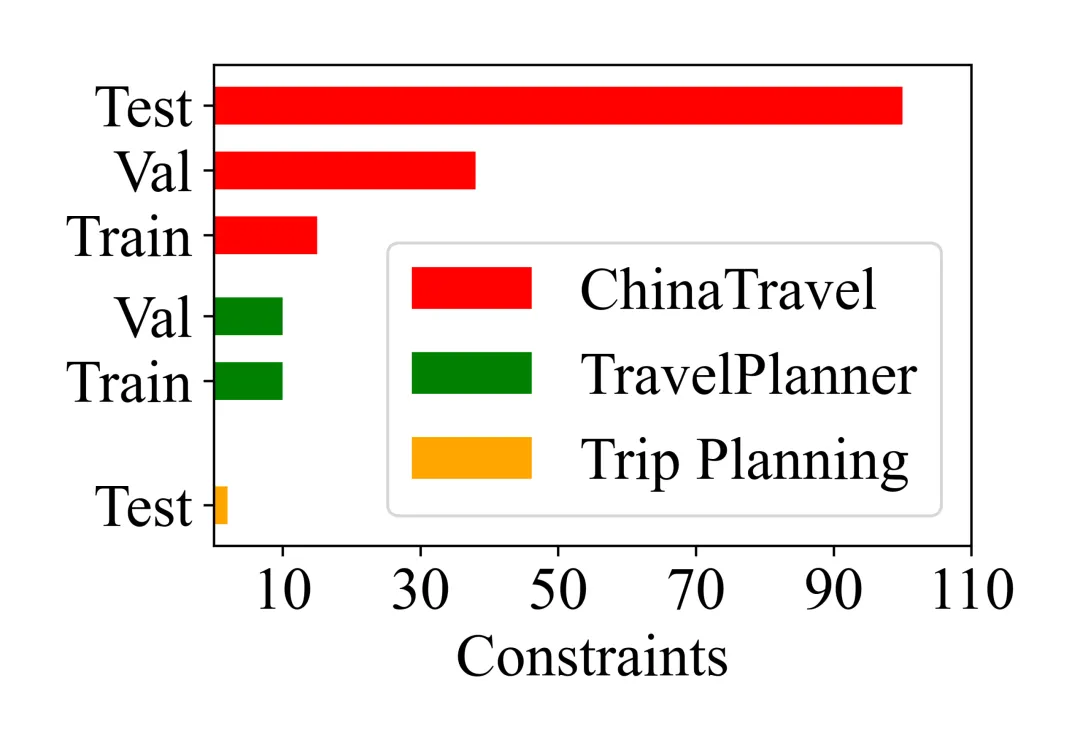
约束类型的数量分布。
📈 语义深度:78.4%的约束必须“结合语境”才能落地
更值得注意的是语义层面的差距。在 Human-Test 上,78.4% 的DSL语句包含需要上下文推理才能填充的“语义POI”;而TravelPlanner 的这一比例只有5.4%,94.6%的需求都在自然语言询问中直接出现过。
差距在哪里?同一句“尝一尝本地菜”,在上海要落到“本帮菜”,在北京要落到“北京菜”;一句“带不吃辣的孩子”,就要自动排除川菜与渝菜。这种语义落地能力,在 TravelPlanner 的模板化 query 中几乎不会被触发。
GPT-4o与DeepSeek-V3在TravelPlanner上的整体准确率都能稳稳站在90% 以上;但放到ChinaTravel后,仅仅是从Literal POI切换到Semantic POI,准确率就出现DeepSeek-V3从94%跌到76%、GPT-4o从79%跌到53%的明显落差。
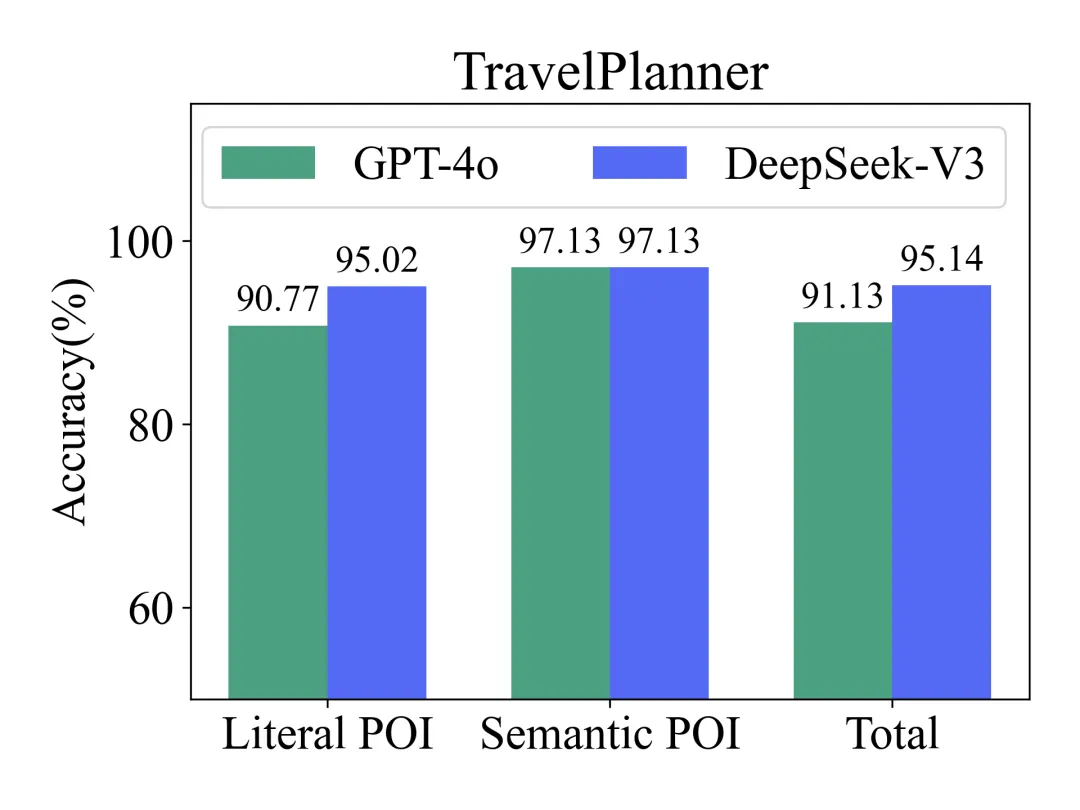
TravelPlanner上的POI识别:Literal与Semantic POI都稳定在90%以上,模板化合成的语义POI几乎不构成挑战。
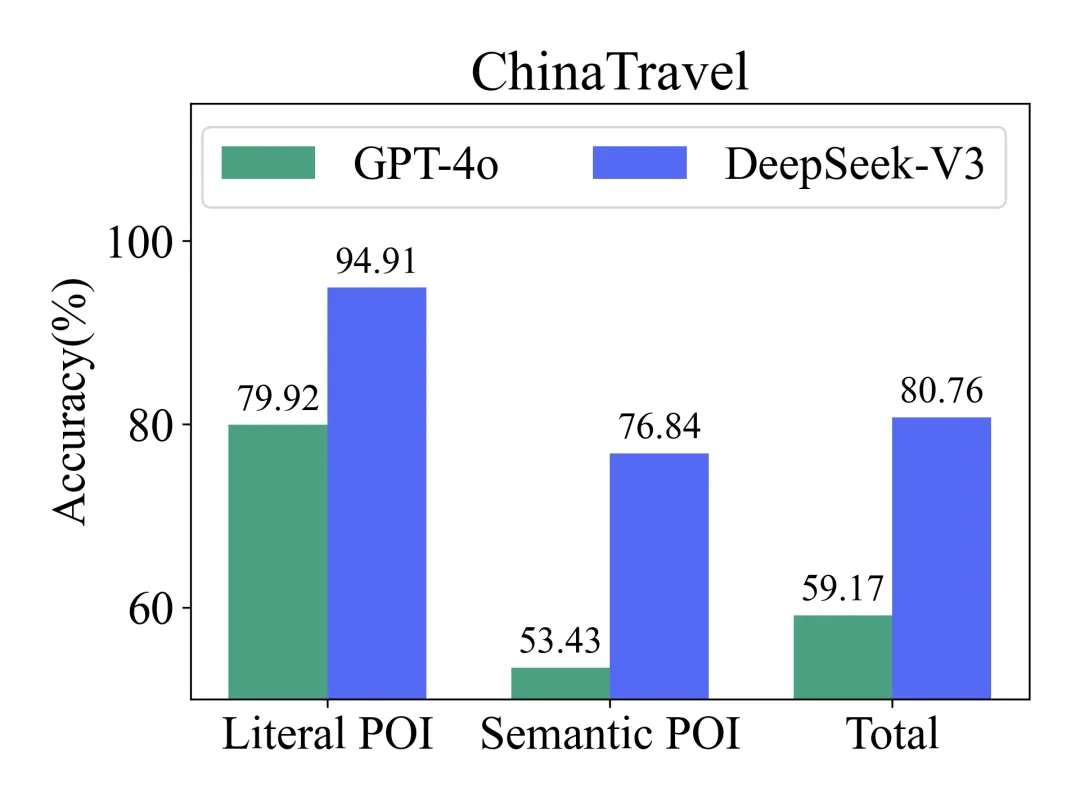
ChinaTravel上的POI识别:从Literal到Semantic出现明显断层,真实需求中的上下文语义落地才是真正的硬骨头。

四个关键发现
下面这张主结果表汇总了Easy/Human-Val/Human-Test三个子集上,五类典型方法(Act、ReAct、NeSy Planning、TTG、LLM-Modulo)配合不同LLM的成绩。其中DR为方案交付率,EPR/LPR为环境与逻辑约束的通过率,C-LPR是我们新设计的“先环境约束后逻辑约束”严格通过率,FPR为最终通过率。
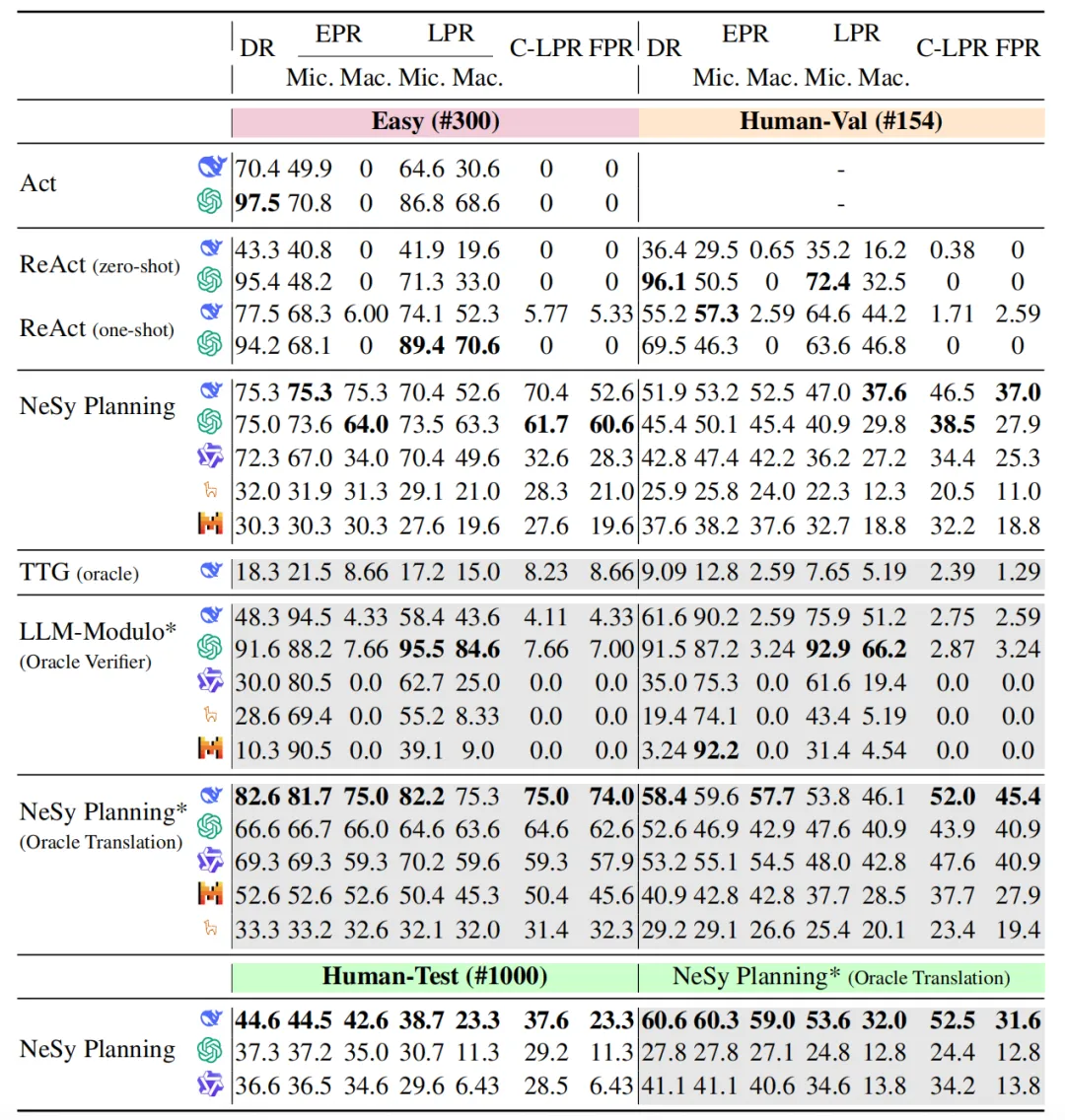
ChinaTravel主实验结果:DR衡量结构化交付能力,EPR/LPR/C-LPR/FPR衡量真实可行性与逻辑通过率。
从这张表可以看出几条趋势:
DR高≠真通过。 纯LLM方法(Act、ReAct)能把Delivery Rate刷到 90% 以上,但EPR/LPR/FPR仍接近零,“形似而神不在”。
TTG几乎走不通。 即使加上Oracle的需求标注,FPR也只有8.66%(Easy)和1.29%(Human-Val),符号求解器在多日行程上被组合复杂度直接拖垮。
NeSy Planning是当下最稳的模式。 配合DeepSeek-V3,它在Easy/Human-Val/Human-Test上分别拿到52.6%/37.0%/23.3%的FPR;如果换上Oracle翻译,Human-Test还能进一步涨到31.6%,体现出DSL翻译这一步还有可观的优化空间。
具体分析,我们可以有以下观察。
🔍 发现一:纯LLM Agent“跑得动”但“做不对”
在ChinaTravel上,GPT-4o+ReAct能把Delivery Rate(结构正确率)刷到96%,交付看上去挺漂亮;但Final Pass Rate(真实通过率)几乎为0,几乎没有任何一条计划能同时满足环境约束和用户逻辑。
为了揭穿这种“结构假通过”,我们专门设计了Conditional Logical Pass Rate(C-LPR) 指标,要求模型必须先通过环境约束、再满足用户逻辑。结果:纯 LLM 方案的 C-LPR 也同步归零。过去它们在某些基准上“蒙对”的那一部分,很大程度上是靠“谎报价格以凑预算”这类捷径虚刷出来的。
🔍 发现二:经典符号求解器“解不出”多日行程
我们把TTG(基于 MILP 的求解器方法)适配进ChinaTravel,结果迎面撞上组合复杂度的墙:约束数量以O(N³T) 量级膨胀。即便把候选POI压到22个(N=22)、时间离散到1小时粒度(T=24/1=24),单条2天行程也要产生约60万条约束。
把SCIP求解器放宽到15分钟/query的搜索预算,在Easy子集上也只能求出18%的可行解;到了3天行程,这一数字跌到6%。
另一条路是LLM-modulo,它用“验证器反馈 + 多轮自修正”来稳住结果,看似聪明;但面对多日行程,3–5轮之后修正能力就快速衰减,继续迭代只会带来无效成本,甚至引入新错误。
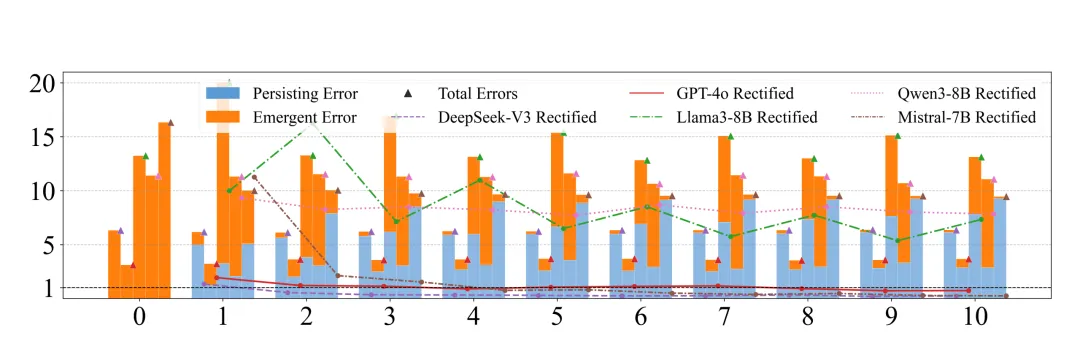
LLM-modulo的错误动力学:修正能力在3–5轮后迅速衰减,后续迭代几乎无效。
🔍 发现三:神经-符号是当下最稳的模式,约束通过率10×于纯LLM
我们提出的NeSy Planning把任务干净地拆成两段:
NL2DSL翻译。用Reflexion加DSL语法检查器迭代,把自然语言需求翻译成逻辑约束。
交互式搜索。 一个带回溯与DSL验证的符号求解器,配合LLM做POI优先级推荐,完成多日多POI编排。
以DeepSeek-V3为底座,NeSy Planning在Easy/Human-Val/Human-Test上的Final Pass Rate分别达到52.6%/37.0%/23.3%。其中Human-Val的37.0%,相比纯LLM方法的2.6%提升了约14倍。
更有意思的是,如果把NL2DSL这一步换成Oracle翻译(即假设自然语言已被完美翻译到DSL),分数还能进一步跃升(Human-Val到45.4%,Human-Test到31.6%)。这说明:符号求解器一定程度上已经具备承载开放需求的能力,卡住智能体的是“自然语言如何被忠实翻译成可组合的逻辑语言”这一步。
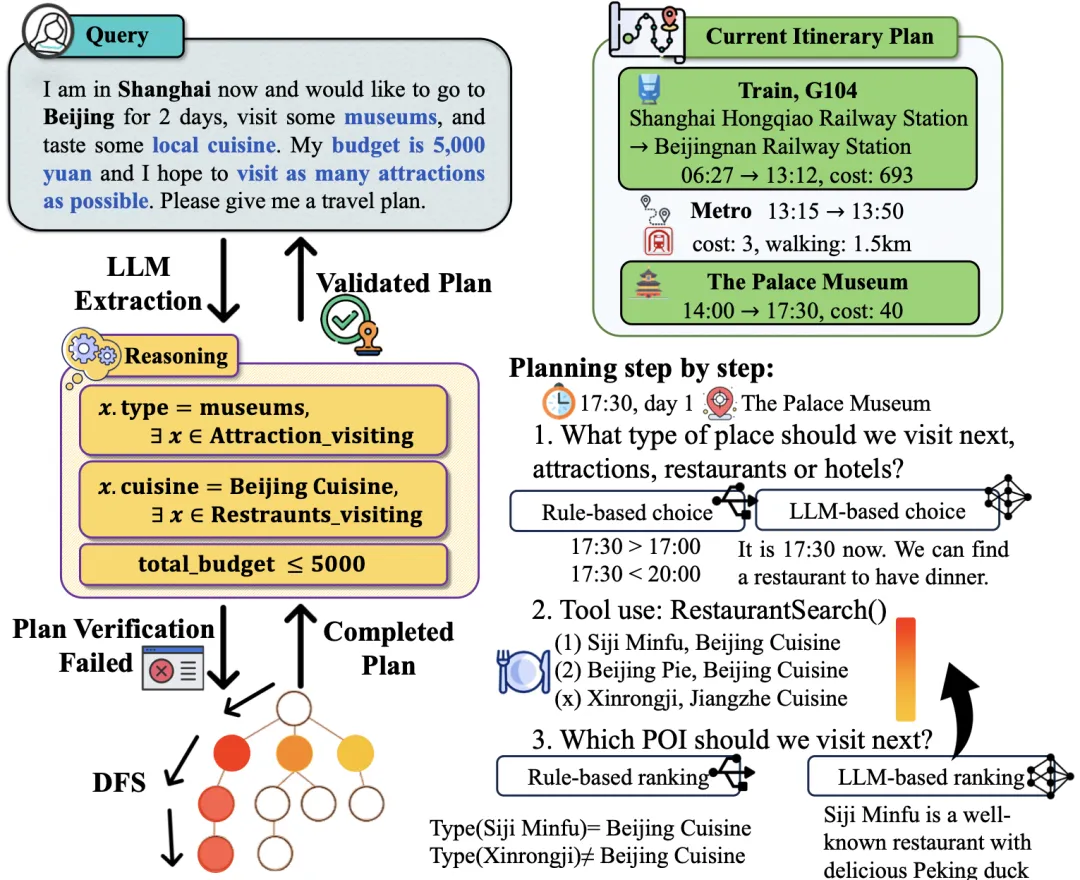
NeSy Planning:先把自然语言翻译为DS 约束,再用带回溯的搜索器完成行程编排。
🎯 发现四:留给社区的四道“难关”
尽管神经符号方法在这类约束满足的旅行规划任务上显著优于纯LLM方法,仍然存在若干瓶颈,我们总结了四道当下难跨过的关卡:
DSL语法合规:基于Reflexion模式的DSL翻译过程能让语法错误快速清零,但代价是Qwen3-8B、Llama3-8B、Mistral-7B都会“倾向保守、忽略约束”,GPT-4o平均也比DeepSeek-V3少抽取2条。看似语法的 error=0,实则在悄悄放弃用户需求。
上下文语义落地: “本地菜”、“不吃辣”、“适合带孩子”这类开放表达,靠in-context prompting无法稳定解决,需要具备领域适应能力的训练范式。
组合泛化:Human-Test中有84%的DSL结构 在训练集里从未出现过,模型在这部分的结构对齐率只有12%,而在已见模式上能达到93%。会抄模板、不会组合,这才是今天LLM在真实需求上的共性短板。
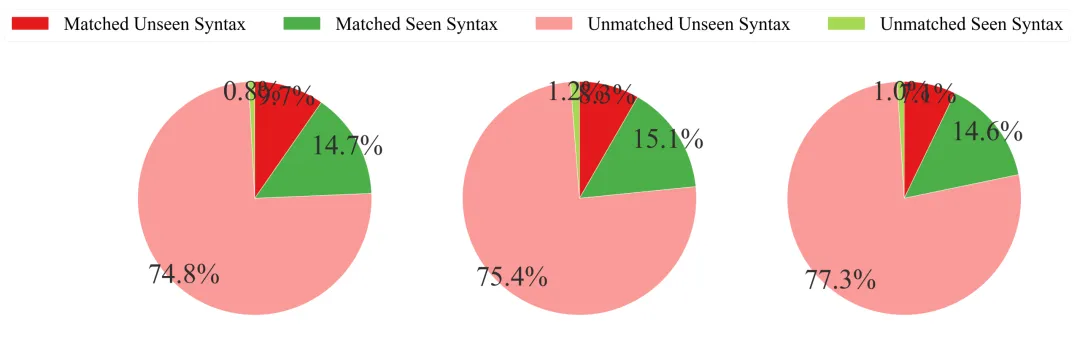
DSL翻译的组合泛化分布(左到右为三种LLM:DeepSeek-V3、GPT-4o和Qwen3-8B):绿色“已见模式且对齐”仅占15%左右,浅红色“未见组合且失败”普遍超过75%。即便是开发集里见过的语法结构也只占16%,模型在剩下84%的真实需求上几乎束手无策。
符号侧搜索效率:神经-符号方法虽然显著提升了约束满足能力,但符号侧的时间开销仍然很高。面对多日、多POI、多约束的旅行规划,回溯搜索容易在组合空间中反复试探,导致在固定时限内无法完成完整行程,DR交付率也因此受限。后续可能需要让LLM更深度地参与符号搜索,例如动态指导分支选择、冲突修复和局部重规划;也可以利用神经-符号方法生成高质量约束满足数据,反过来训练LLM,提升其在复杂约束下的可行规划能力。

展望写在最后:把“开放”重新放回评测里
过去几年,旅行规划常被用作语言智能体的典型落地场景。但在很多评测中,真实旅行需求被压缩成了闭集里的“填空题”:用户意图被拆成固定槽位,约束类型可以预先枚举,验证规则也相对容易写死。
ChinaTravel试图回答的是另一个问题:当需求来自真实用户、表达方式不再受模板限制、约束之间可以自由组合时,今天的语言智能体还能不能给出一份真正可用的行程?
从实验结果看,答案并不简单。纯LLM Agent能生成结构完整的计划,却很难稳定满足真实约束;传统符号求解器具备严格推理能力,却会在多日、多POI、多约束的组合空间中遭遇效率瓶颈;神经-符号方法目前最稳,但仍受制于自然语言到DSL的忠实翻译、上下文语义落地、组合泛化和符号搜索效率。
这也是ChinaTravel团队希望带给社区的核心价值:它不是为了在一个已饱和的闭集基准上继续刷分,而是把真实开放需求重新放回评测中心,帮助研究者看清语言智能体究竟在哪些环节失效,以及下一步应该优化什么。
🏁 挑战赛预告。沿着这一方向,ChinaTravel团队将在IJCAI 2026举办第二届旅行规划智能体挑战赛。如果你关注LLM Agent、神经-符号推理、约束规划、工具调用或中文复杂需求理解,这将是一个在更接近真实世界的旅行规划场景中检验方法、交流思路、共同推进可靠语言智能体研究的机会。
📌 挑战赛主页:https://chinatravel-competition.github.io/IJCAI2026/





相关文章
发表评论
评论列表
- 这篇文章还没有收到评论,赶紧来抢沙发吧~