
基于Python的文化旅游信息公开管理平台 计算机毕业设计选题 【源码-文档报告-代码讲解】
基于Python的文化旅游信息公开管理平台 计算机毕业设计选题 【源码-文档报告-代码讲解】基于Python的文化旅游信息公开管理平台 计算机毕业设计选题 【源码-文档报告-代码讲解】 
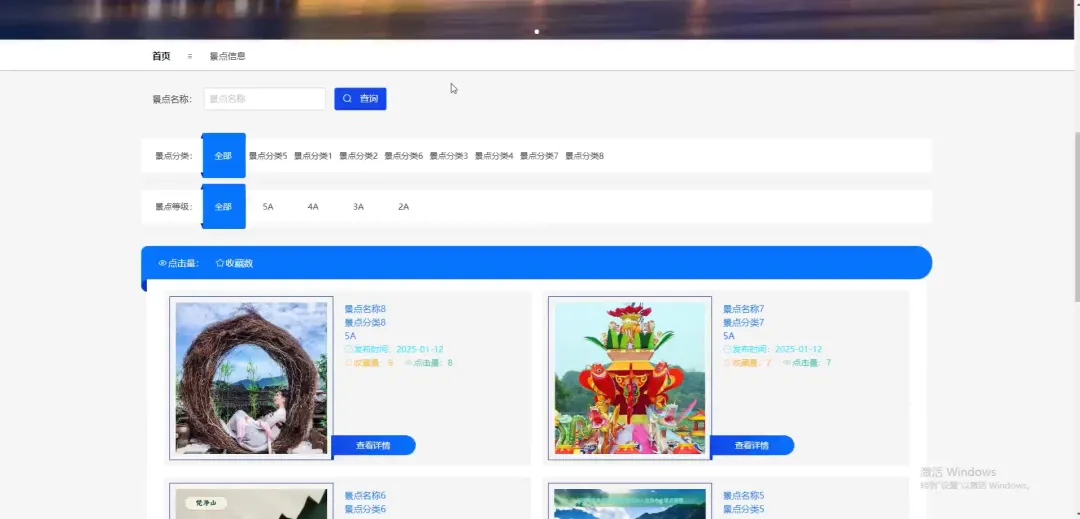
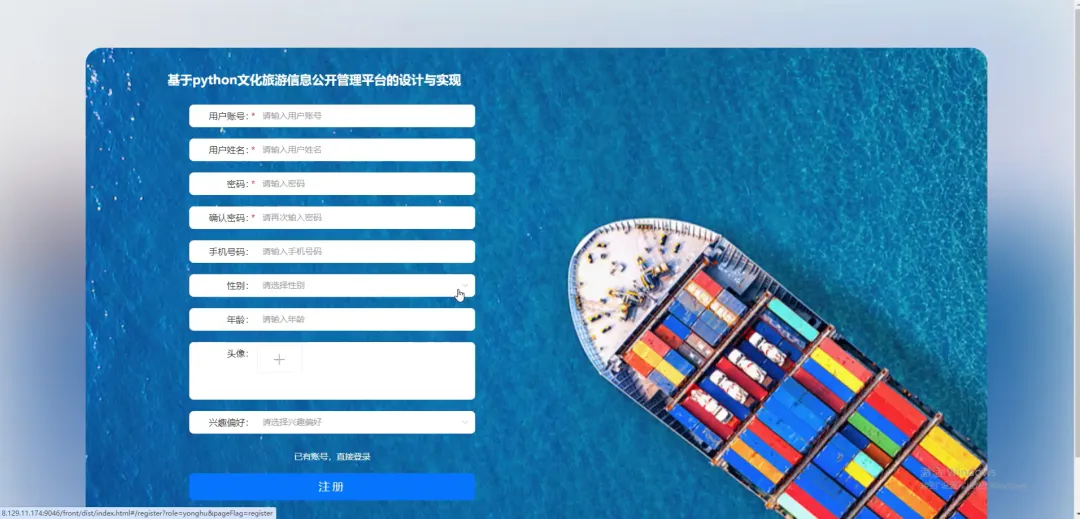
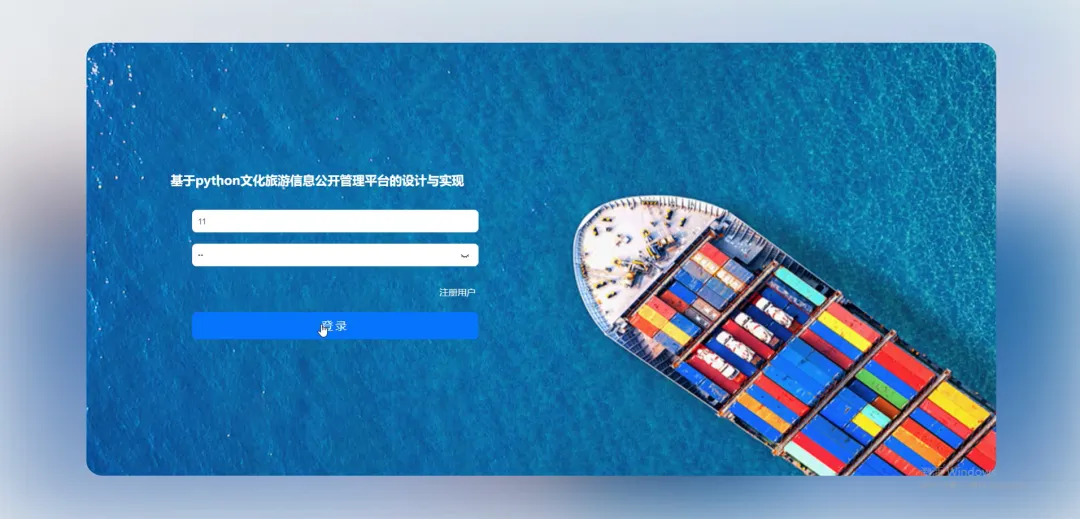
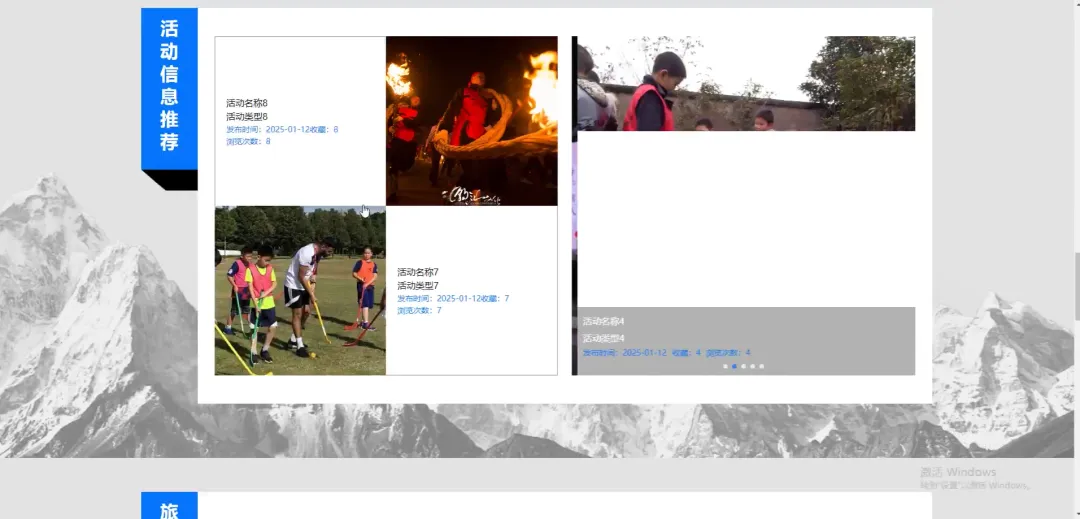
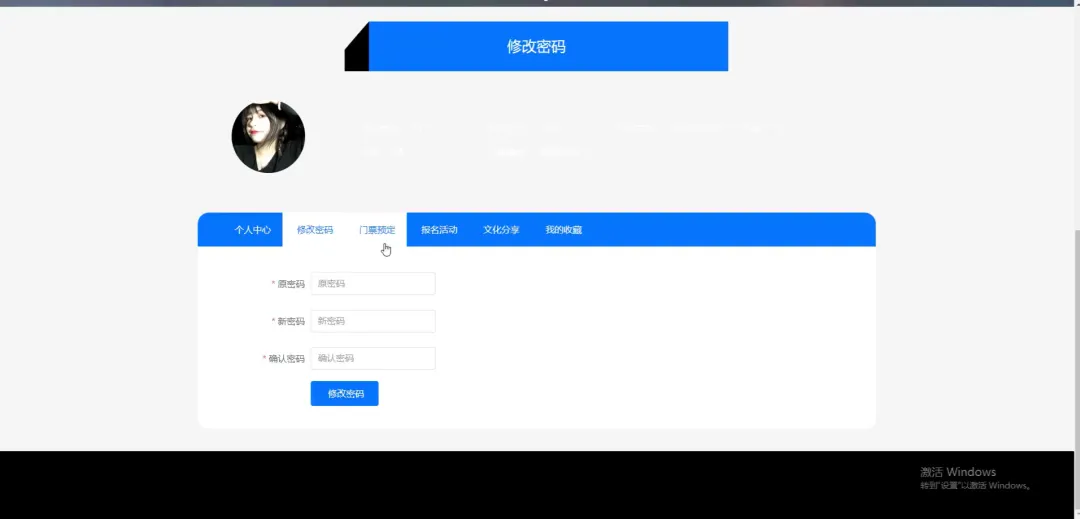
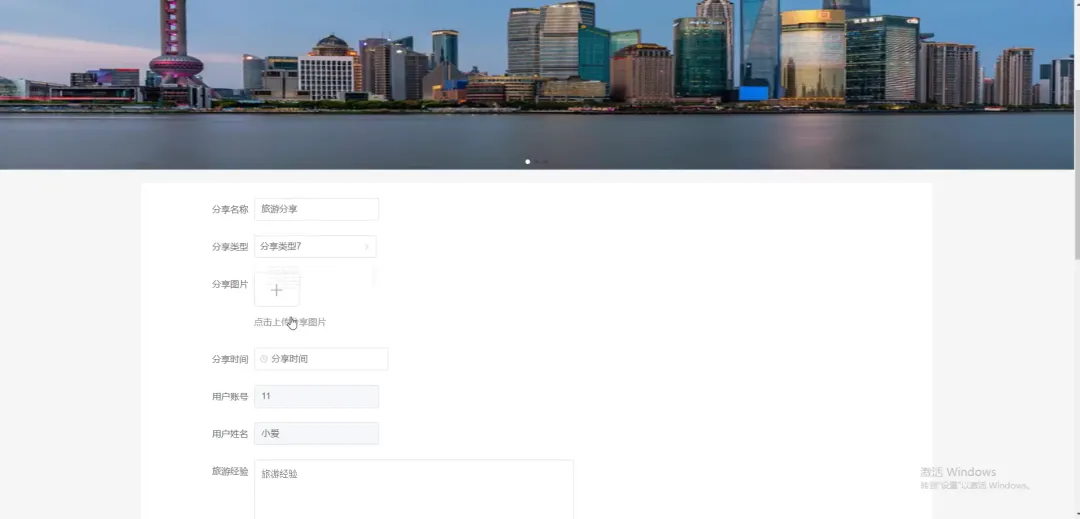
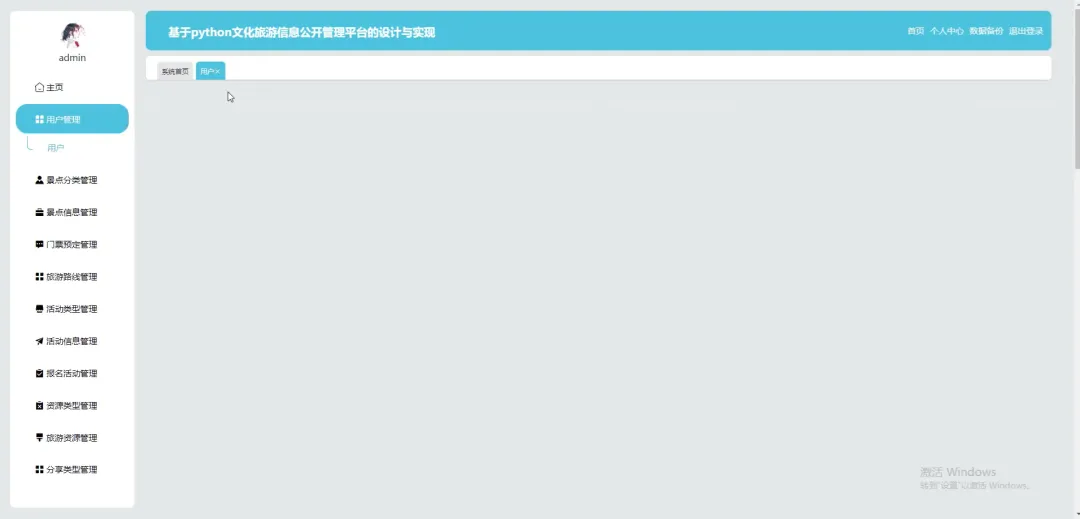
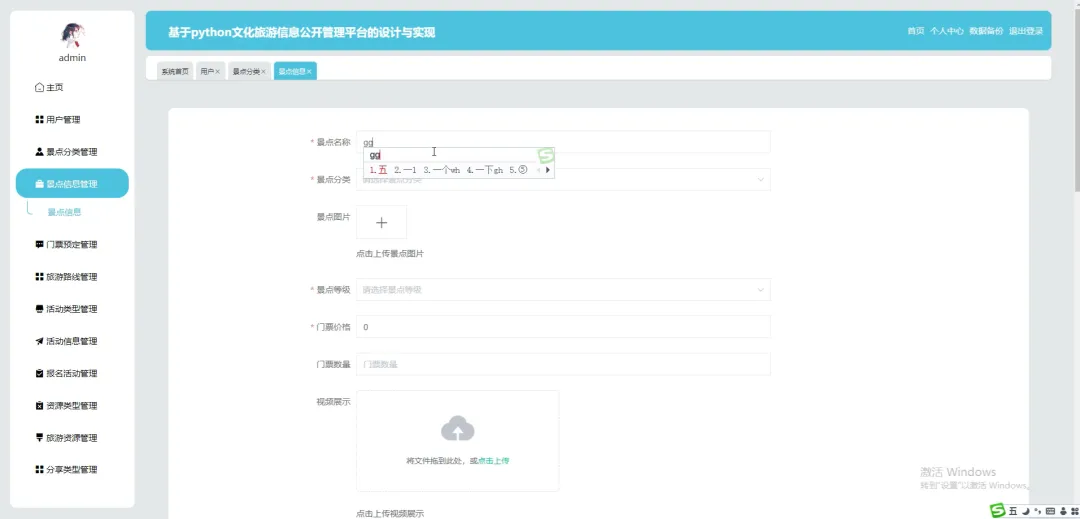
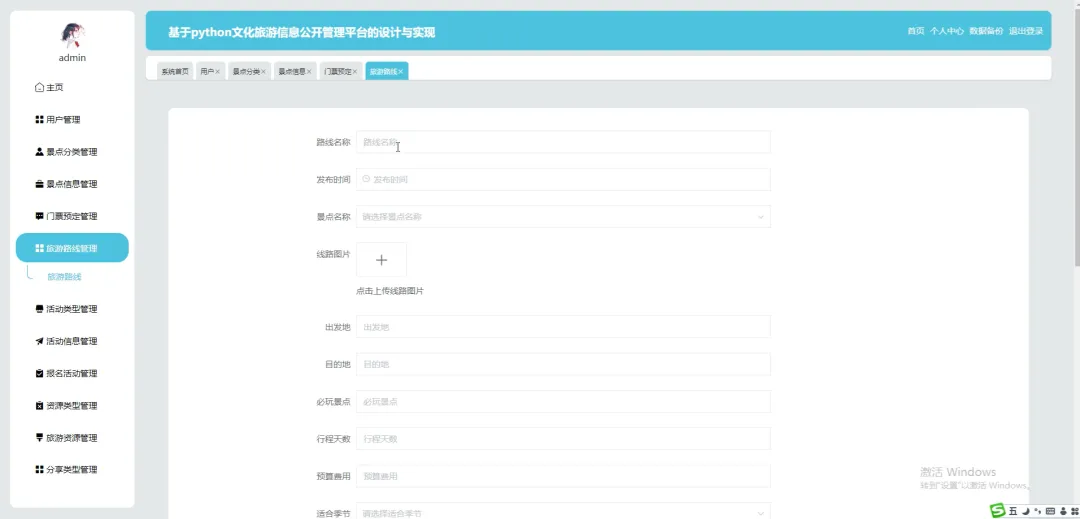
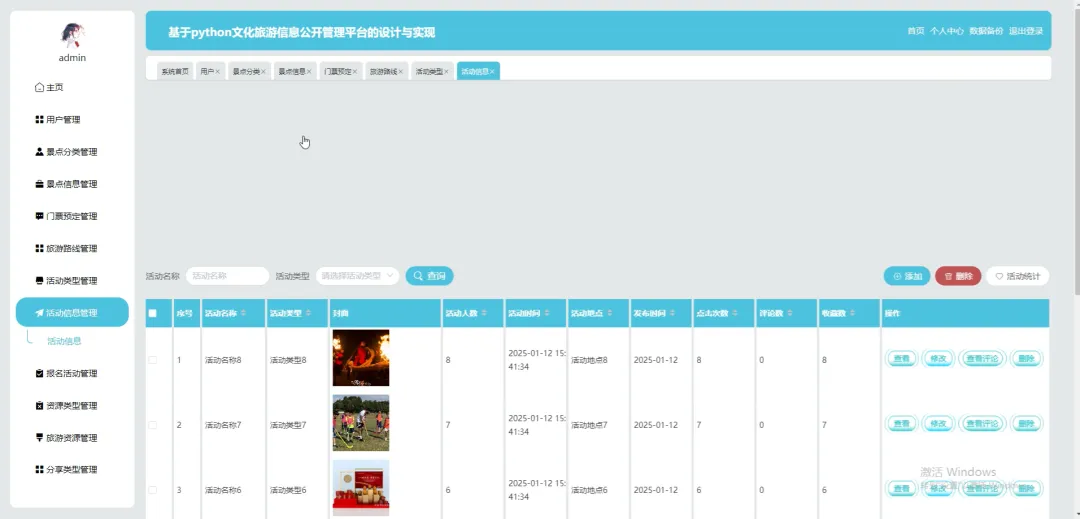
计算机毕业设计小明哥 PART1 文化旅游信息公开管理平台-系统功能 本系统《基于Python的文化旅游信息公开管理平台》是一个采用B/S架构设计的现代化Web应用,旨在为游客和管理者提供一个高效、便捷的文化旅游信息交互枢纽。系统后端核心基于Python语言及Django框架进行构建,利用其强大的ORM功能和快速开发特性,实现了业务逻辑的清晰分层与数据的高效处理;前端则采用Vue.js结合ElementUI组件库,通过前后端分离的开发模式,为用户带来了响应迅速、交互流畅的界面体验。在数据持久化层面,系统选用MySQL关系型数据库来存储景点信息、文化资料、用户数据及评论内容等核心实体,确保了数据的一致性与可靠性。平台主要面向两大用户群体:普通游客和管理员。游客可以通过平台浏览详细的文化旅游景点介绍、查询开放时间与票价、阅读其他游客的真实评论与评分,并进行个人收藏管理;管理员则拥有后台管理权限,能够对景点信息、新闻公告、用户评论进行全方位的增删改查操作,并可视化的查看平台运营的基础数据,从而实现对文化旅游信息的集中化、规范化和动态化管理,极大地提升了信息发布的效率与游客的规划体验。 PART2 文化旅游信息公开管理平台-系统技术 开发语言:Java+Python(两个版本都支持)后端框架:Spring Boot(Spring+SpringMVC+Mybatis)+Django(两个版本都支持) 前端:Vue+ElementUI+HTML 数据库:MySQL 系统架构:B/S 开发工具:IDEA(Java的)或者PyCharm(Python的) PART3 文化旅游信息公开管理平台-背景意义 选题背景随着社会经济的发展和人们生活水平的提高,旅游已经从单纯的观光行为向深度文化体验转变,越来越多的人渴望在旅途中感受独特的地方文化与历史底蕴。然而,当前许多文化旅游信息散落在各个政府网站、旅游社平台、社交媒体上,信息孤岛现象严重,游客往往需要花费大量时间和精力去筛选、甄别信息的准确性与时效性,这无疑增加了旅行规划的难度。同时,一些地方的文化旅游资源未能得到系统性的整合与有效的线上推广,导致其知名度不高,难以吸引到潜在游客。因此,开发一个能够集中、权威、动态地展示区域文化旅游信息的公开管理平台,便成为了一个切实的需求。本项目正是在这样的背景下提出的,尝试利用现代Web技术,构建一个连接游客与文化资源的桥梁,解决信息不对称的问题,为游客提供一站式的信息获取服务,也为文化资源的数字化保护与传播贡献一份力量。 选题意义 作为一个毕业设计项目,本系统的意义更多体现在实践探索和应用价值上,而非颠覆性的行业变革。对于游客而言,这个平台提供了一个可靠的信息来源,他们可以在这里找到经过整理的景点介绍、实用的游览建议以及其他游客的真实反馈,这能帮助他们更好地规划行程,避免踩坑,提升整个旅行的质量和满意度。对地方文旅管理部门或相关机构来说,系统扮演了一个数字化的宣传窗口和管理助手的角色,通过这个平台可以更便捷地发布官方信息、推广特色文化活动,并且能直接收集到用户的评价和需求,为后续的服务改进和决策提供数据参考。对我个人而言,完成这个项目是一次宝贵的全栈开发实践,它让我完整地经历了从需求分析、技术选型、系统设计到编码实现和测试部署的全过程,将课堂上学到的Python、Django、Vue、MySQL等知识点真正融会贯通,锻炼了解决实际问题的能力,为未来的学习和工作打下了坚实的基础。 PART4 文化旅游信息公开管理平台-演示视频 PART5 文化旅游信息公开管理平台-演示图片 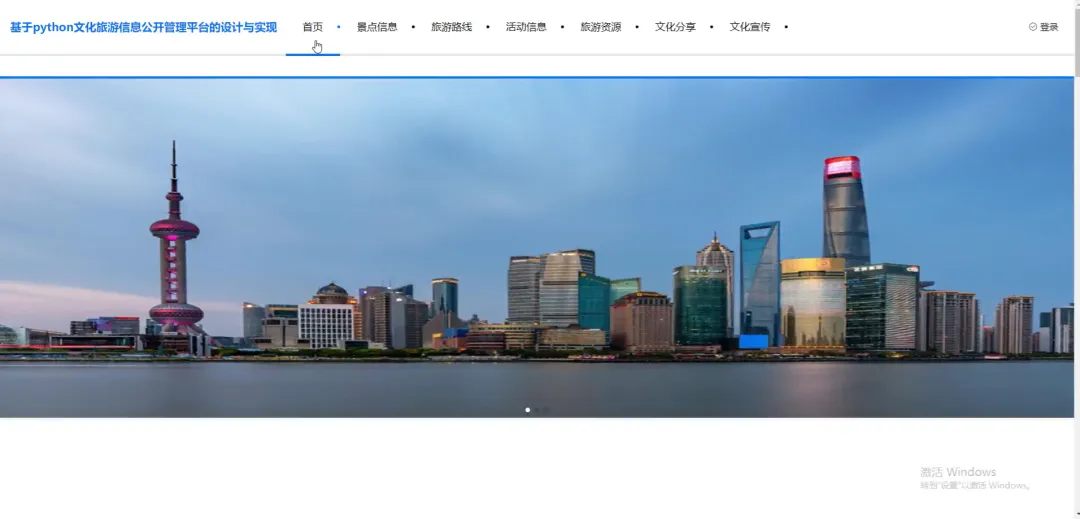
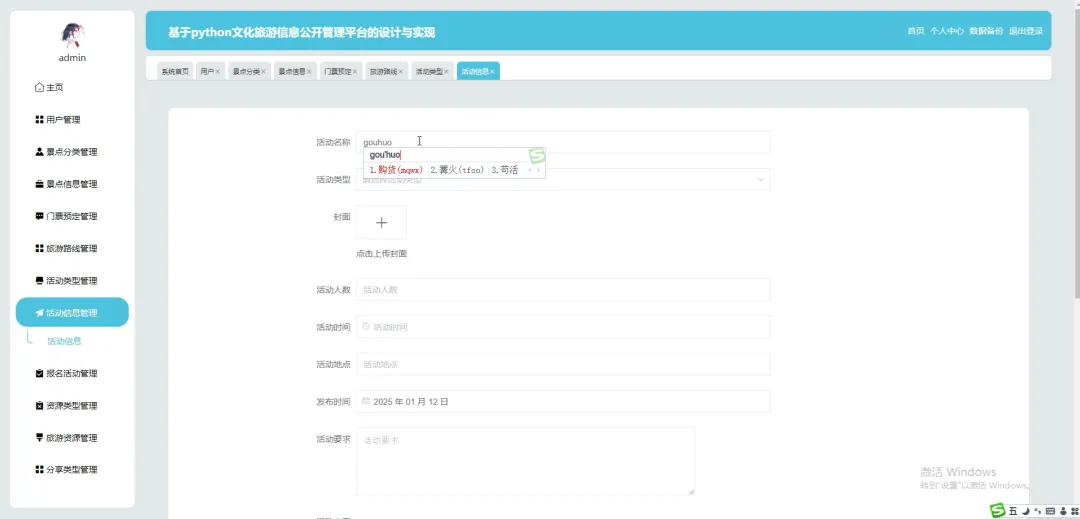
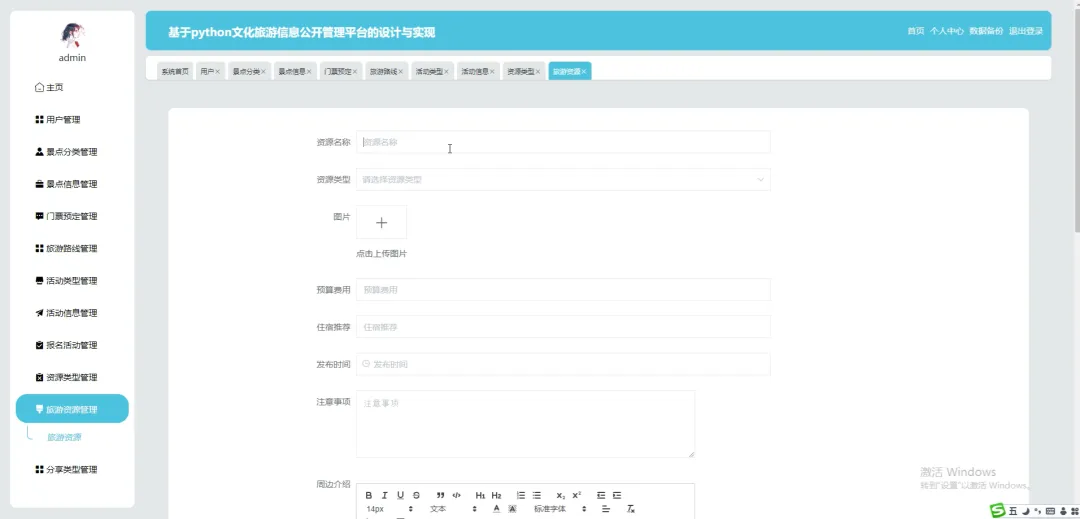
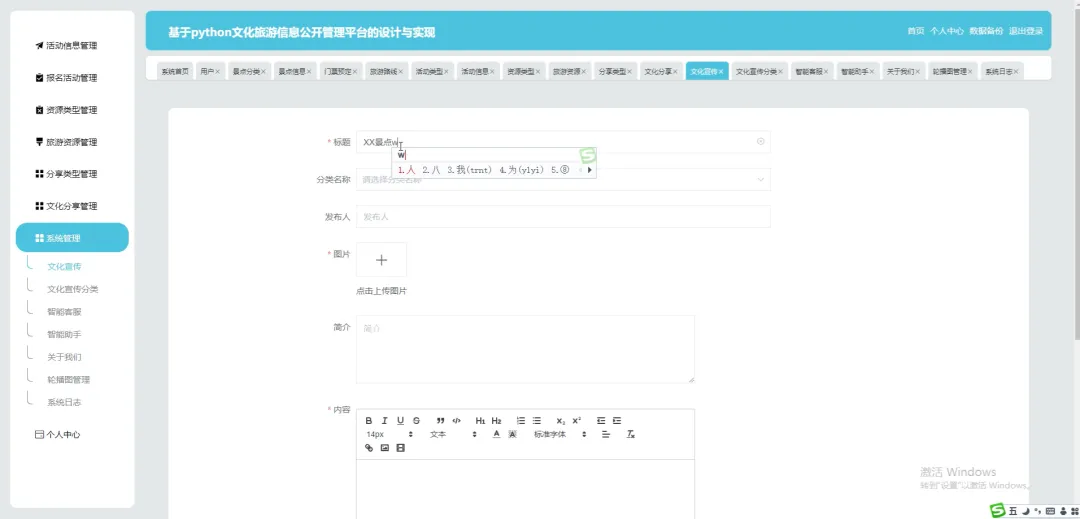
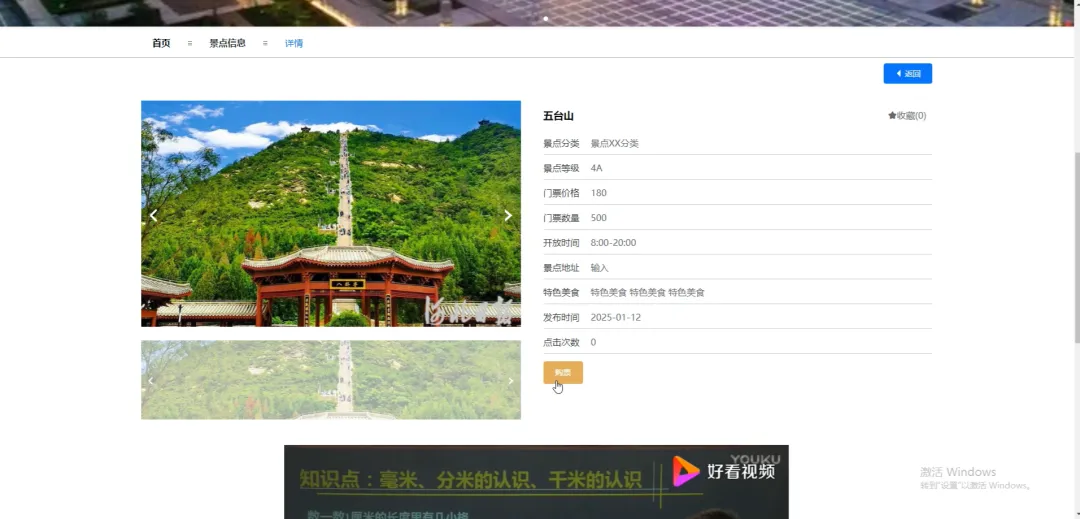
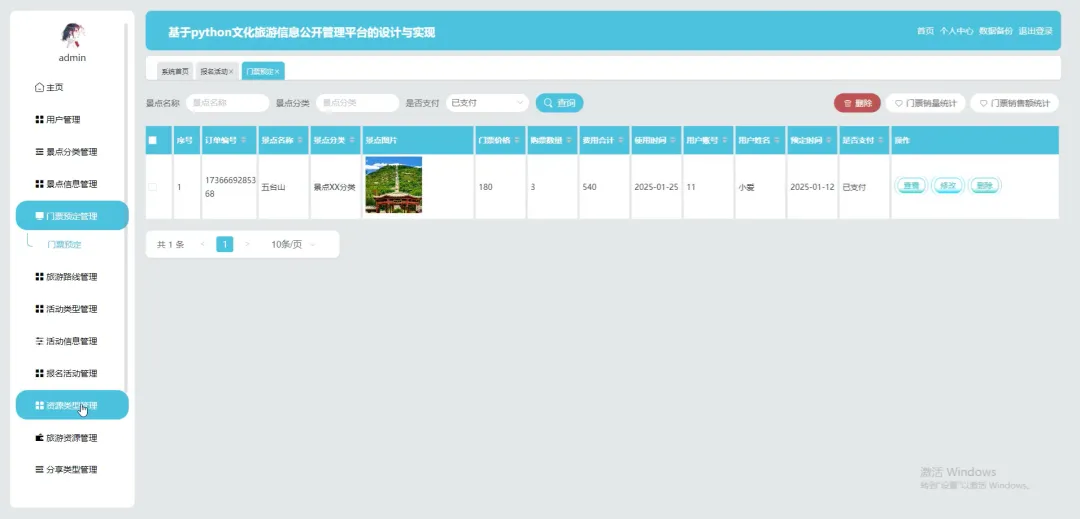
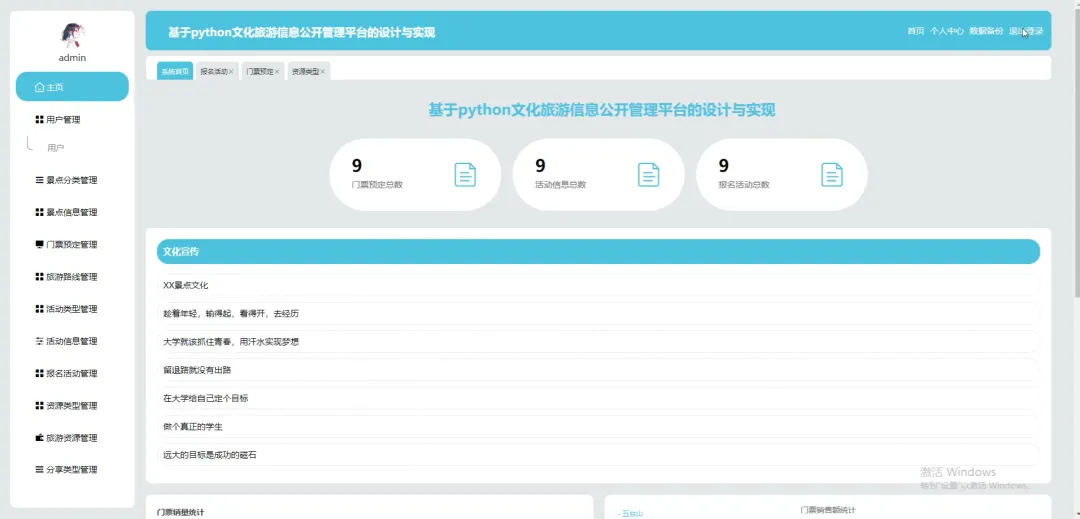
PART6 文化旅游信息公开管理平台-代码展示 END 计算机毕业设计小明哥 全程辅导 顺利过关
已关注
关注
重播 分享 赞
# 以下代码模拟了在Django视图中的核心业务逻辑处理,并集成了Spark用于离线数据分析的场景# 假设此为推荐系统模块,首先初始化SparkSession用于离线分析用户行为日志from pyspark.sql import SparkSessionspark = SparkSession.builder.appName("TourismRecommendation").getOrCreate()# 核心功能1:管理员添加或更新景点信息def manage_attraction(request):if request.method == 'POST':attraction_id = request.POST.get('attraction_id')name = request.POST.get('name', '').strip()description = request.POST.get('description', '').strip()location = request.POST.get('location', '').strip()if not name or not location:return JsonResponse({'status': 'error', 'message': '景点名称和位置不能为空'})try:if attraction_id:attraction = Attraction.objects.get(id=attraction_id)attraction.name = nameattraction.description = descriptionattraction.location = locationelse:attraction = Attraction(name=name, description=description, location=location)attraction.save()return JsonResponse({'status': 'success', 'message': '操作成功', 'attraction_id': attraction.id})except Attraction.DoesNotExist:return JsonResponse({'status': 'error', 'message': '景点不存在'})except Exception as e:return JsonResponse({'status': 'error', 'message': f'服务器错误: {str(e)}'})return JsonResponse({'status': 'error', 'message': '请求方法错误'})# 核心功能2:用户提交评论并更新景点平均分def submit_comment(request):if request.method == 'POST' and request.user.is_authenticated:user = request.userattraction_id = request.POST.get('attraction_id')content = request.POST.get('content', '').strip()rating = int(request.POST.get('rating', 0))if not (1 <= rating <= 5):return JsonResponse({'status': 'error', 'message': '评分必须在1-5之间'})if not content:return JsonResponse({'status': 'error', 'message': '评论内容不能为空'})try:attraction = Attraction.objects.get(id=attraction_id)if Comment.objects.filter(user=user, attraction=attraction).exists():return JsonResponse({'status': 'error', 'message': '您已经评论过此景点'})comment = Comment.objects.create(user=user, attraction=attraction, content=content, rating=rating)comments = Comment.objects.filter(attraction=attraction)avg_rating = comments.aggregate(avg_rating=Avg('rating'))['avg_rating']attraction.average_rating = round(avg_rating, 1)attraction.save()return JsonResponse({'status': 'success', 'message': '评论成功', 'new_avg_rating': attraction.average_rating})except Attraction.DoesNotExist:return JsonResponse({'status': 'error', 'message': '景点不存在'})return JsonResponse({'status': 'error', 'message': '无效的请求'})# 核心功能3:基于Spark分析的个性化推荐(模拟离线计算过程)def generate_recommendations(user_id):# 假设user_behavior_log是一个包含(user_id, attraction_id, action_type)的HDFS路径# 这里用本地模拟数据代替data = [(1, 101, 'view'), (1, 102, 'view'), (2, 101, 'view'), (2, 103, 'view'), (3, 102, 'view'), (3, 104, 'view')]columns = ["user_id", "attraction_id", "action"]df = spark.createDataFrame(data, columns)user_actions = df.filter(col("user_id") == user_id).select("attraction_id").distinct()viewed_attractions = [row['attraction_id'] for row in user_actions.collect()]co_viewed_df = df.alias("df1").join(df.alias("df2"), col("df1.attraction_id") == col("df2.attraction_id")).filter(col("df1.user_id") != col("df2.user_id"))similar_users = co_viewed_df.filter(col("df1.user_id") == user_id).select(col("df2.user_id").alias("similar_user")).distinct()recommendations_df = similar_users.join(df, similar_users.similar_user == df.user_id).filter(~col("attraction_id").isin(viewed_attractions))final_recommendations = recommendations_df.groupBy("attraction_id").count().orderBy(col("count").desc())recommended_ids = [row['attraction_id'] for row in final_recommendations.limit(5).collect()]recommended_attractions = Attraction.objects.filter(id__in=recommended_ids)return list(recommended_attractions.values())




相关文章
- 高铁直达!珠海十大旅游景点精选,想来珠海旅游,看这个攻略就够了!!!
- 谁说旅行必须做攻略?在琼海街头随意Citywalk,才是打开春天的正确方式
- 《旅游安全实务手册》之特殊旅游项目篇
- 高铁直达!廊坊十大旅游景点精选,想来廊坊旅游,看这个攻略就够了!!!
- 适合老人的三亚攻略:北京7天自由行,亚特兰蒂斯度假区轻松玩
- 蚌埠必读!蚌埠旅游实用全攻略(精品干货)
- 国外旅游|购物英语全攻略(试衣 + 退换货一次搞懂)
- 高铁直达!三亚十大旅游景点精选,想来三亚旅游,看这个攻略就够了!!!
- 别再让几百万“睡”在账上!用银行保函置换旅游质保金,最快3天盘活现金流
- 【通知公告】文化和旅游部办公厅关于申报“人工智能+文化和”应用试点的通知
发表评论
评论列表
- 这篇文章还没有收到评论,赶紧来抢沙发吧~