
成果动态 | 旅游文本情感计算:在人工计算模型与机器学习之间寻找最优解

1
背景介绍

随着社交媒体与在线点评平台的蓬勃发展,海量的非结构化文本数据成为了理解游客行为与目的地形象的重要资源。情感分类作为文本挖掘的核心技术,其准确性直接影响到研究结论的可靠性。目前,旅游研究者主要依赖两种路径:一是基于情感词典的人工计算模型(Manual Computing Model),二是有监督的机器学习模型(Machine Learning Model)。2017年,团队开发了基于情感词典的旅游情感评价模型(TSE,Tourism Sentiment Evaluation)(刘逸等2017),并设定了核心变量——情感乘数,用以捕捉旅游者在社交媒体表达“倾向于用丰富的正面词汇表达适度好感,而用克制的负面词汇表达强烈不满”的语言特征。
尽管近年来人工智能热潮使机器学习受到广泛推崇,甚至被默认为情感计算的“最优解”,但其在语境复杂且专业性强的旅游场景下是否具有绝对优势,尚缺乏系统性的实证证据。2021年团队进行初步尝试,沿用2017年开发的TSE模型,将其与6种主流的机器学习模型在旅游文本情感计算这个情境中进行比较(刘逸等2021),结果显示TSE模型的准确率仅位列第三,这一结果一度令基于情感词典和规则的研究路径陷入困境。然而,在2024年关于景区和酒店评论清洗的研究中,团队通过大规模人工判读发现中文在线旅游评论存在显著的“语言积极性偏见”,偏见系数为2~2.5之间(刘逸等2024)。这一发现让我们意识到,所谓的“偏见系数”在本质上与TSE模型中的“情感乘数”高度同构,且数值上的差异揭示了一个关键问题:情感乘数并非一个普适的常数,而是一个随语料环境动态变化的变量。
基于此发现,团队反思了2021年实验中因沿用情感参数可能导致的效能低估。在最新一轮的研究中,我们邀请语言学专家深度参与,基于新语料对情感乘数进行动态测度与优化,并简化了计算流程,旨在重新评估精细化调校后的TSE模型与前沿机器学习模型在旅游情境下的效能边界。该研究于2025年网络首发于Current Issues in Tourism。全文简介如下:
图1 两类模型PK(GPT-5.2生成)
2
研究问题

本研究旨在回应旅游文本情感分析中的“工具选择焦虑”问题,核心研究问题如下:
在处理旅游点评这类具有高度行业特征的文本时,经过参数优化后的人工计算模型与最先进的机器学习模型在情感分类准确率上表现如何?
在不同的数据规模、研究成本与精度需求下,研究者应如何科学地选择技术方案,以实现研究目标与工具的最优匹配?
3
研究方法

本研究构建了一个涵盖多种旅游场景的大型语料库,由此提炼出情感词典,并设定语义规则和程度副词,利用问卷调查数据(Q.T. Data)和人工阅读数据(R.T. Data)作为基准,测定最优的情感乘数,形成优化后的TSE模型。随后研究选取了包括深度学习算法在内的多种主流的机器学习模型与优化后的TSE模型比对。我们以均方根误差(RMSE)作为核心评价指标。均方根误差对极端误差高度敏感,其值越小,表明模型情感分类效果越好。数据处理流程如图2所示。
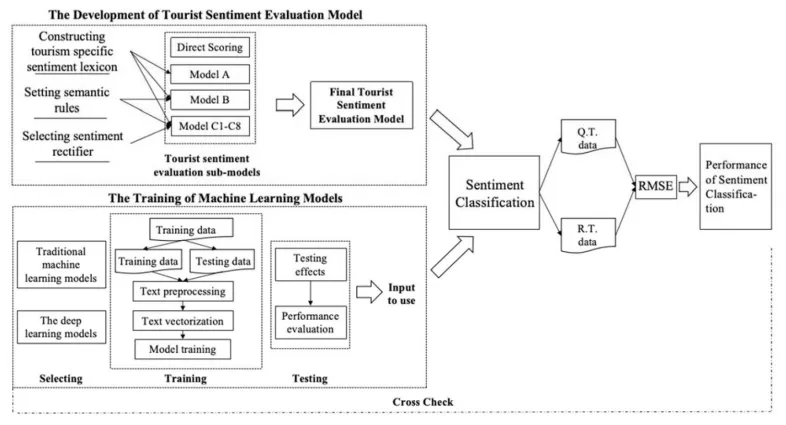
图2 研究框架
本研究将情感乘数相关规则更新为:如果正面得分超过或等于负面得分绝对值的 e 倍,该评论就会被归类为正面评论。相反,如果正面得分在负面得分绝对值的 0.5×e 倍到 e 倍之间,则被归类为中性评论。如果正面得分等于或低于负面得分绝对值的 0.5×e 倍,则被归类为负面评论。情感分类计算公式如图3所示:
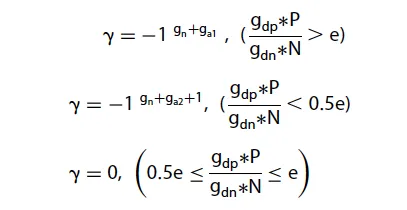
图3 TSE模型情感计算公式
4
研究结论

结果表明,最佳的情感乘数为6(子模型C6最佳),如图4所示。
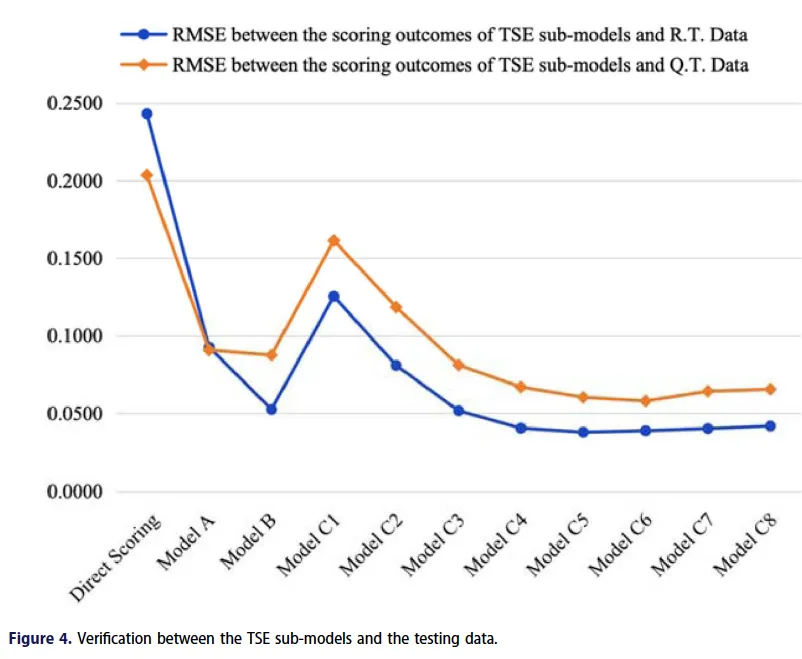
图4 情感乘数测定
对比实验表明,优化后的TSE模型在情感分类效果上排名第一,其结果与人工判读及问卷调查的一致性最高,优于所有参评的机器学习模型。如图5所示。
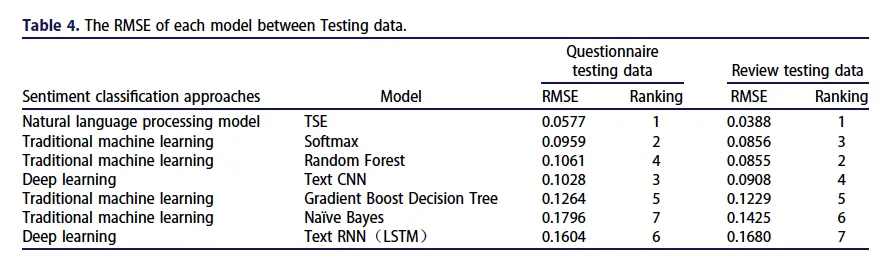
图5 实验结果
该研究结果在一定程度上打破了“智能技术崇拜”:虽然机器学习模型在处理大规模、多维度的复杂语料时具有泛化优势,但在特定垂直领域(如旅游情景),经过精细调校的人工计算模型在稳健性与解释力上更胜一筹。
更重要的是,本研究发现,情感乘数并非固定常数,而是受数据来源和语境影响的动态变量,使用时必须进行针对性校验。本研究也再次证实,直接采用在线旅游评分来代替游客情感满意度的做法存在较大偏差。
5
研究贡献

在理论层面,本研究为旅游情境下的情感分析提供了批判性的实证证据,挑战了“人工智能模型具有压倒性优势”的固有认知,强调了领域知识在旅游信息学中的核心价值。
在实践层面,本研究为旅游管理者和研究人员提供了操作性建议。对于预算有限、追求语义解释力的小型课题组,基于词典的TSE模型(已开放使用:http://www.teeglab.com/mytse/)是高性价比的选择。而对于处理超大规模平台数据的机构,则可协同使用机器学习模型。这一结论有助于研究者走出技术迷雾,实现旅游研究工具与科学问题的精准匹配。
成果引用:Liu, Y., Han, F., Meng, L., Lai, J., & Gao, X. (2026). Textual sentiment classification in tourism research: Between manual computing model and machine learning. Current Issues in Tourism, 1-22.
DOI:https://doi.org/10.1080/13683500.2025.2452893
参考文献:
刘逸, 保继刚, 朱毅玲.基于大数据的旅游目的地情感评价方法探究[J].地理研究,2017,36(06):1091-1105.
刘逸,孟令坤,保继刚,等.人工计算模型与机器学习模型的情感捕捉效度比较研究——以旅游评论数据为例[J].南开管理评论,2021,24(05):63-74.
刘逸, 肖文杰*, 关僖, 高璇, 郑子钰. (2024). 中文在线旅游评论的语言积极性偏见研究[J]. 旅游科学,1-16
文案 | 刘逸教授团队 周泽根
编辑 | 王雅瑶
审核 | 赵莹




相关文章
发表评论
评论列表
- 这篇文章还没有收到评论,赶紧来抢沙发吧~